



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
浅谈Web攻击日志分析 及日志发展的过去现在与未来
时间:2022-06-30 19:05:08 编辑:袖梨 来源:一聚教程网
前言
谈到日志分析大多数人的感觉是这是一个事后行为,场景当黑客成功将网站黑了。运营人员发现的时候安全人员会介入分析入侵原因,通过分析黑客攻击行为往往会回溯最近几天甚至更加久远的日志。
处理过程。
个人认为日志分析的过程分为3个阶段:

• 过去:
在之前很多网站的运营日志并不多少,只有几G多的可能几十,上百G,当出现了攻击行为时,利用grep、perl或者python脚本可以来完成,但这也是基本偏向于事后阶段。原始阶段,通过grep关键字来发现异常,这样并不能达到实时分析的结果,往往也是需要到出事后才能介入。 在后来,我们在服务器上部署了perl脚本想通过实时tail日志来发现攻击者的行为从而进行一个好的分析。这里的问题是对服务器负载压力大,运维人员未必会协助你部署,比较苦逼。那么我们能否在事前阶段介入呢? 答案是有的,通过下文介绍的方法来逐步实现。
• 现在:
现在是大数据时代数据的最根本的体现就是大,随着电子商务的兴起。每天日志量上亿或者上十几亿基本成为了主流,如果还是依赖之前的脚本或者grep根本无法完成既定的分析,更谈不上能实时分析。
大数据给我们带来了很多针对大量数据处理的方案,比如hive(离线分析)、storm(实时分析框架)、impala(实时计算引擎)、haddop(分布式计算)、以及hbase,spark这样的技术。
那么在有了数据之前,我们应该做点什么能够支撑我们的安全数据分析平台呢?
我觉得可以分为几个阶段来进行:
数据收集。
数据处理。
数据实时计算。
数据存储 分为2个部分:离线和实时。
首先第一点没有数据的话,就不要往下看了。
安全分析的基础是数据,所有的数据来源都源自web日志,从业务的角度来说,这些都是业务日志,但是在我的眼里这些数据是“蜜罐”。
日志当中存在好的坏的人,我们的目标就是从中筛出坏人。
基于大数据的技术如此多,通过架构及技术选型,选择的数据类型是这样:

数据收集通过flume实现,数据订阅使用kafka来实现,数据实时计算框架使用strorm来实现实时处理,数据存储通过2个方面来实现,实时存储和离线存储。
flume: Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
kafka: Kafka1是linkedin用于日志处理的分布式消息队列。
storm: 实时计算框架,通过流处理来实现对数据的实时处理,storm具有实时性高、吞吐量大,低延迟,实时等特点,适合的场景是源源不断的数据源。 下图为storm ui界面:

• 日志基本处理:
通过这些方式,我们有了日志后,需要观察日志的格式理解其各个字段的意思,将日志格式化方便进行提取,此处使用正则完成匹配。 比如一段nginx 日志规则:
log_format combined '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent"';
对于恶意攻击日志,在这里的关键字有哪些用的上呢? $request、$status、$body_bytes_sent、http_user_agent等。
通过格式化整理工作,在有了大量数据后,我们要做的就是尽可能去除眼前的障碍。
这些障碍包括各种扫描,各种爬虫,各种有意无意的入侵行为。
对于基本过滤,我们关注的主要是2个:疑似成功的和不成功的,这些通过日志可以做基本的判别。
HTTP code = 403,404,502,301,这些基本都可以判断为不成功的攻击。
而htttp code 等于200和500状态基本可判断为疑似“成功攻击”。那么在有了这些基础的筛选后,可以去除较多的无用数据。
我们的目标:记住我们要抓的那种隐藏在大量障碍数据下的攻击,并不能仅仅依靠这些来实现分析,这是不专业且不负责任的行为。
规则定制:
通过规则定制,可以结合攻防经验加之前分析过程中发现的问题整理成为规则,加入到storm实时分析job中,来发现攻击行为,将攻击行为入库。发现的多少,完全取决于规则的多少与精准,包括正则的编写, 规则的定制。
Storm规则捕获:
在storm里的实现方式是,通过正则表达式匹配关键字,如:phpinfo。
Storm里的数据流向是storm接入Kafka topic,我们可以通过tupple接收到的数据,将数据做预处理。
这个部分storm是使用prepare来做预处理,这里可以将正则表达式写入到prepare里。
Storm job是使用java编写的,这里匹配phpinfo的代码是:

有了数据的预处理后,需要执行搜索,正则表达式的逻辑就是,非黑即白,有就匹配没有就略过,这里忽略大小写。
Storm 使用execute来做执行层的逻辑判断,通过匹配tupple里是否包含Phpinfo,如果是则显示已找到phpinfo,如果不是则不回显结果。
通过将storm job,上传到Nimbus后,执行结果可发现如下信息,可实时发现phpinfo关键字,storm job的编译使用mvn来做。

最后通过数据库将匹配后的结果输出到数据库内,匹配到的结果是这样子的:
storm 实时计算支持本地调试和远程调试,本地访问http://hostname/phpinfo.php,storm 抓取到的信息:

写入数据库内的信息:

最后写入数据库后信息,可以看到14:23:41秒测试,14:23:49秒插入数据库。

通过Phpinfo 这个关键字匹配到的信息如下:

• 数据可视化:
通过基础的数据分析可以将结果绘成图,这样做的好处可以将攻击的监控时间段拉长不在拘泥于单一的数据库查询,当然不是为了可视化而可视化这就失去不 了了其意义,可视化的目的是为了运营需要。
表不如图,要做的足够好就应该考虑用户体验,但这样的可视化是有用的吗?

答案未必,可视化的目标是为了让别人清晰的看出来你所做的数据分析的真谛。
• 数据存储:
数据分析后,需要有针对性的存储,以备后续联合分析,数据存储主要采用离线和实时,实时主要是提供一天内的攻击趋势展现。
• 数据分析:(重点)
通过将这些规则的检查结果写入数据库,通过数据库查询方式将日志筛选,提炼出攻击时间,攻击ip,攻击次数,ip来源归属地以及一天有哪些时间段攻击最多,由此可以给黑客画一张活动轨迹图。
判断黑客的技术能力,是否是常客,以及作案动机是什么,但比较悲观的是即使分析了这些,对于攻击行为还是需要采取一定的行为,比如把前top20 提取出来封掉。
其次就是攻击行为是否可进一步分析?如果只是这样分析是人人都会的,需要将这些数据结合漏洞来分析比如出现个shellshock漏洞,php cgi远程代码执行漏洞是否能发现?经过一段时间内的分析是可以总结个趋势的。
这一切的重点是特征、关键字,通过关键字势识别,就像识别你是胖的、瘦的、高的、矮的一样,先将你以类别区分出来,然后进行分析。
分析的前提是,先建立表,你想做啥查询,数据库表结构需要设置好,比如:
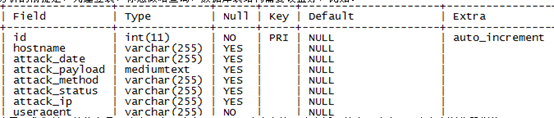
这里,我们关心的信息是:攻击日志、攻击payload、攻击方法、攻击返回状态、攻击ip、攻击者浏览器指纹。
• 确定分析范围:
需要确定想找到哪些问题?sql注入、xss、文件包含、目录遍历、爆破、各种扫描器扫描。将这些信息汇集后,写入到规则中,通过storm实时计算,运算一段时间我们就会得到各种各样的数据,有了分析的基本样本。
分析,其实就是个汇总的过程,使用mysql就可以完成。
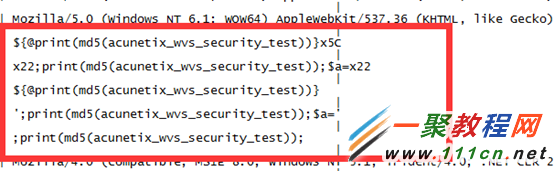
我们所有的分析都是从安全的角度来进行的,所以看看大家感兴趣的内容,有哪些user_agent?这里是awvs的扫描器指纹
各种各样的各种扫描数据:
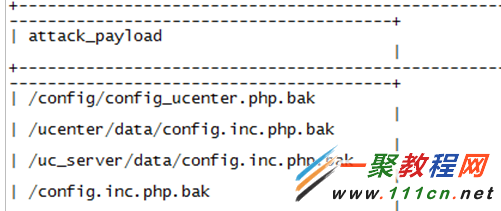
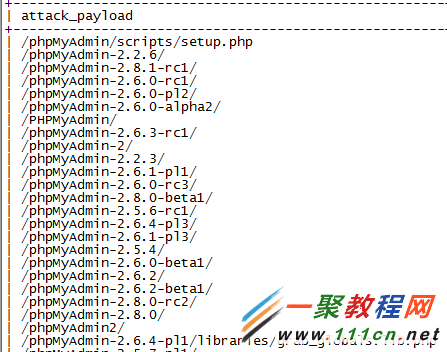
从数据分析上来看,攻击者似乎对discuz的.bak文件情有独钟。又或者,我们来看看攻击者最热衷哪些phpmyadmin?
以及各种各样的xss:

以及我们熟悉的struts2?
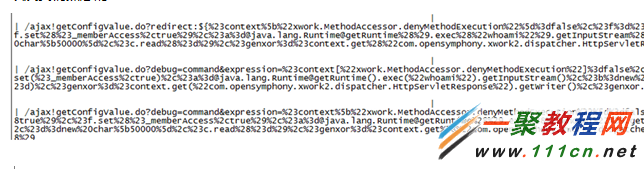
等等这些都是有特征,可被查找到的,查找到了其实不是目标,我们的目标是能不能在智能点?
因为很多的攻击数据,都是无意义的,怎么从这些当中筛选出真正的危险,这部分是自动化测试的范畴,这里先不讲。
通过对这些数据的分析,可以比较轻易的知道有哪些东西是攻击者感兴趣的,以及市面上是否出现了1day被大规模利用。
未来:
日志分析的未来,一定是以数据为前提的,通过机器学习和数据挖掘算法来实现对日志及攻击趋势的预测。
最后日志分析是个不断进化的过程,不断修炼。
数据库层面的压力比较大,使用Mysql对于千万级别的数据库查询有点不太适合,后续会考虑hbase等来处理。
以及考虑到使用诸如:贝叶斯算法来对历史数据进行评分及策略调整。
相关文章
- 《弓箭传说2》新手玩法介绍 01-16
- 《地下城与勇士:起源》断桥烟雨多买多送活动内容一览 01-16
- 《差不多高手》醉拳龙技能特点分享 01-16
- 《鬼谷八荒》毕方尾羽解除限制道具推荐 01-16
- 《地下城与勇士:起源》阿拉德首次迎新春活动内容一览 01-16
- 《差不多高手》情圣技能特点分享 01-16