



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
python模拟登陆之验证码与cookies的同步处理思路
时间:2022-11-14 23:00:33 编辑:袖梨 来源:一聚教程网
自动登陆可能是写爬虫的第一步,如果都不能登陆,很多东西爬不到的。这也不是第一次写包含验证码识别的自动登陆脚本了。这次有点被坑住了,把这次的记录下来。
这次要自动登陆的网站地址是:2013年株洲市中小学教师全员培训 /IndexPage/Index.aspx
先说下思路,好多人写那些不需要验证码识别的自动登陆脚本很容易,只要保存好cookies就可以了,但是对于需要验证码的网站就总是登陆不上去。
对于需要验证码的网站的自动登陆脚本的步骤:(以上面我说的那个网站为例,对于python和其他语言,思路和步骤都是适用的)
a.先打开登陆页面,获得cookies。
b.再访问验证码的地址。验证码是动态的,每次打开都不一样。
c.识别验证码。这里就需要你处理、识别刚才得到的验证码。自己去找验证码(captcha)识别库,python可以用 pytesser(这个库是调用PIL来处理识别的) 、openc 之类的 或者可以人工识别然后手动输入验证码。
d.构造post请求数据(request data)和请求头部(request head) ,然后 将构造的请求 post给网站
f.获取 响应(response)信息,并通过测试来验证登陆是否成功。
或者直接跳过a步骤:
b.直接访问验证码的地址。(这里之所以能跳过 a ,是因为当我们打开 验证码地址时候,已经能获得所有我们需要的cookies 和登陆的验证码 ,所以就没必要 先操作 a 步骤)
c.识别验证码。这里就需要你处理、识别刚才得到的验证码。自己去找验证码(captcha)识别库,python可以用 pytesser(这个库是调用PIL来处理识别的) 、openc 之类的 或者可以人工识别然后手动输入验证码。
d.构造post请求数据(request data)和请求头部(request head) ,然后 将构造的请求 post给网站
f.获取 响应(response)信息,并通过测试来验证登陆是否成功。
#############################################################################
这两个步骤的区别无非是多了个访问登陆页面的步骤,对登陆没什么影响。我这里用浏览器演示下 第一种步骤(即a ,b,c,d,e,f步骤),下篇文章开始更具体的操作,获取修改cookies,post数据构造等。
通过下面的步骤来验证我们的思路(还是刚才的网站):
用到的工具:
firefox浏览器中的firebug扩展 。还可以使用Fiddler,或者httpfox,wireshark 。我这用firebug方便。chrome也有firebug。
1.访问登陆页面获取cookies (相当于a 步骤)
先清空火狐的缓存和cookies ,打开firebug,监控所有网页。然后打开登陆页面:/IndexPage/Index.aspx 。我们得到了第一个验证码:2073 ,可以通过firebug看到所获得的cookies ,
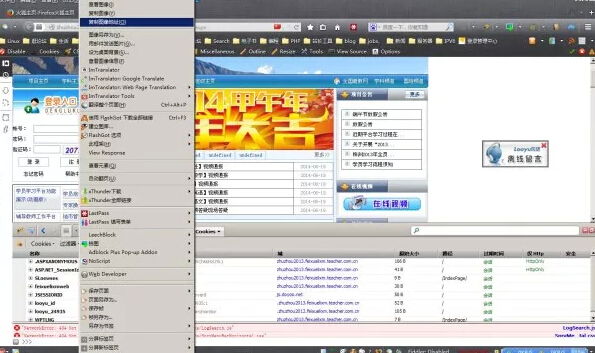
测试下这个验证码地址是否有效:在不关闭刚才登陆页面的 同时用火狐打开验证码的地址,的确得到了一个验证码,也是我们获得的第二个验证码:2876 ,cookies 还是原来的cookies。
python模拟登陆代码;
| 代码如下 | 复制代码 |
|
# -*- coding: utf-8 -*-
#避免 UnicodeEncodeError: 'ascii' codec can't encode character. 的报错
#下面这段是关键了,将为urlib2.urlopen绑定cookies
#登陆页面 #要post的url
##打开登陆页面, 以此来获取cookies 。 但是因为 ##打开验证码页面就可以获取全部cookies了,所以可以直接跳过这一步。算是可有可无的
#提取验证码地址(用pytesser 识别, 自己网上找教程安装)
#设置cookie的值,因为post request head 需要 返回 cookie (不是cookies ,是将cookies的格式处理后的值)
#请求数据包
#post请求头部
#将响应的网页打印到文件中,方便自己排查错误
try: #因为后面要从网页查找字符来验证登陆成功与否,所以要保证查找的字符与网页编码相同,否则无非得到正确的结论。建议用英文查找,如css中的 id, name 之类的。 #在返回的网页中,查找“你好” 两个字符,因为只有登陆成功后才有两个字,找到了即表示登陆成功。建议用英文 response.close() |
|
#这个代码很随意,但是容易看,需要的活,可以写成函数。还有就是urlopen()在大量登陆及检验过程中,可能read(0因为网络阻塞而timeout(超时) ,需要设置urlopen() 的超时时间,或者多次发送请求
总结:在需要输入验证码的网页写自动登陆登陆脚本时候。关键是保证cookies 和 验证码 是同步的。如果直接打开验证码地址就能获得 登陆所需的全部cookies (此时验证码和cookies必定是同步到的),那么就不必 先打开登陆页面来获取cookies,后打开验证码地址获取 验证码。何必多此一举呢?
相关文章
- 漫蛙漫画入口精准定位-漫蛙漫画入口官方推荐极速直达通道 03-18
- 手机wpsppt动画效果加入怎么做 03-18
- 豆包手机Ola-Friend限时抢购-豆包手机Ola-Friend官方购买通道 03-18
- toonme苹果ios取消订阅的方法介绍 03-18
- 歪歪漫画-官方首页登录入口 03-18
- 绿洲社交app怎么赚钱 在绿洲赚钱方法 03-18