



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
k-means聚类算法介绍 k-means聚类算法怎么用
时间:2022-06-24 17:45:22 编辑:袖梨 来源:一聚教程网
前提条件
特定领域的经验要求:无
专业经验要求:无行业经验
不需要机器学习的知识,但是读者应该熟悉基本的数据分析(如,描述性分析)。为了实践该示例,读者也应该熟悉Python。
K-means聚类简介
K-means聚类是一种无监督学习,用于有未标记的数据时(例如,数据没有定义类别或组)。该算法的目标是在数据中找到分组,变量K代表分组的个数。该算法迭代地分配每个数据点到提供特征的K分组中的一个。数据点基于特征相似性聚集。K-means聚类算法的结果是:
1. K聚类的质心,它可以用来标记新数据
2. 训练数据标记(每个数据点被分配到一个单一的集群 )
聚类允许你发现和分析有机形成的组,而不是在查看数据之前定义组。下面例子中“选择K”的步骤描述如何确定组的数目。
集群的每个质心都是特征值的集合,它定义所产生的组。检查质心特征权重可以用来定性解释每个集群代表什么样的组。
这篇K-means聚类算法涵盖了:
-
使用K-means的常见商业案例
-
运行该算法所涉及的步骤
-
使用一个配送车队数据的Python示例
商业用途
K-means聚类算法用来查找那些包含没有明确标记数据的组。这可以用于确定商业假设,存在什么类型的分组或为复杂的数据集确定未知组。一旦该算法已运行并定义分组,任何新数据可以很容易地分配到正确的组。
这是一个通用算法,可以用于任何类型的分组。用例的一些例子是:
-
行为细分
-
根据购买历史细分
-
根据应用程序、网站或平台上的活动细分
-
定义基于利益的角色
-
基于活动监视创建图表
-
库存分类
-
按销售活动分
-
按生产指标分
-
传感器测量数据分类
-
检测运动传感器中的活动类型
-
图片分组
-
分离音频
-
健康检测中的分组
-
检测机器人或异常
-
来自机器人的单独有效活动组
-
清理孤立点检测的有效活动组
此外,监测是否一个被跟踪的数据点随着时间在组之间切换,这可以用来检测数据有意义的变化。
算法
Κ-means聚类算法使用迭代细化来产生最终的结果。该算法的输入是聚类的数目Κ和数据集。数据集是每个数据点特征的集合。该算法从为K质点初始估计开始,它可以随机生成或从数据集中随机选择。然后该算法在以下两步之间迭代:
1. 数据分配步骤
每个质点定义一个聚类。在本步骤中,每个数据点被分配到离它最近的质心,基于欧氏距离的平方。更准确地说,如果ci是集合C质心的集合,然后每个数据点x被分配到一个聚类,基于
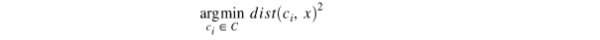
dist( ・ )是标准(L2)欧氏距离。数据点集分配每个ith聚类质心Si。
2. 质心更新步骤:
在本步骤中,质心被重新计算。这通过分配所有数据点的平均值到质心的聚类来实现。
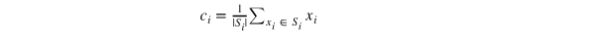
该算法在步骤1和步骤2之间迭代直到满足停止标准(如,没有数据点改变聚类,距离之和最小化,或者达到了最大的迭代次数)。
该算法保证收敛到一个结果。其结果可能是一个局部最优(例如,不一定是最好的结果),意思是使用随机开始质心评估多个运行的算法可能给出更好的结果。
选择K
上述算法查找聚类和一个特定的预先选定K的带标记的数据。为了查找数据中的聚类个数,用户需要为在K值范围内运行K-means聚类算法并比较结果。总体而言,目前还没有确定K精确值的方法,但可以使用以下技术获得准确的估计。
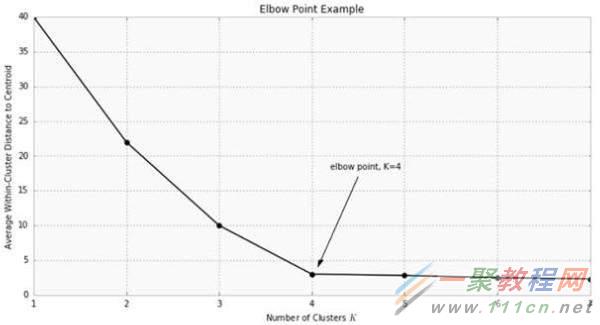
通常用于比较不同K值结果的度量之一是数据点和它们聚类质心的平均距离。由于增加聚类的数量总是会减少数据点的距离,增加K总
是会降低这个度量,当k与数据点数相同时达到极值。因此,这个度量不能作为唯一的指标。相反,平均距离到质心作为一个函数的K
被绘制并且急剧下降率的地方“肘点”,可用于大致确定K。
有许多其它技术确认K,包括交叉验证、信息标准、信息理论跳法、影像法和G-means算法。另外,监测数据点跨组分布可以深入了解
该算法如何为每个k分割数据。
示例:应用K-Means聚类到配送车队数据
举例来说,我们将展示K-means算法如何处理配送车队司机数据的样本数据集。简单起见,我们只会看两个司机特征:平均每天驾驶距离和一个司机>5mph以上速度限制的平均时间百分比。总
体而言,该算法可以用于任何数量的特征,只要数据样本的个数比特征的数量大的多。
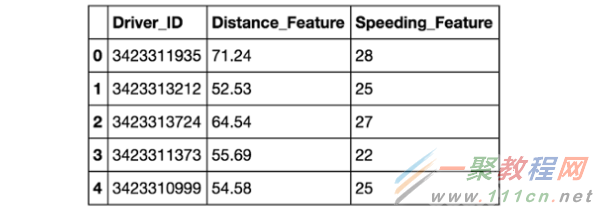
步骤1:清洁和改造数据
在本例中,我们已经清理并完成了一些简单的数据转换。数据样本作为pandas DataFrame如下所示。
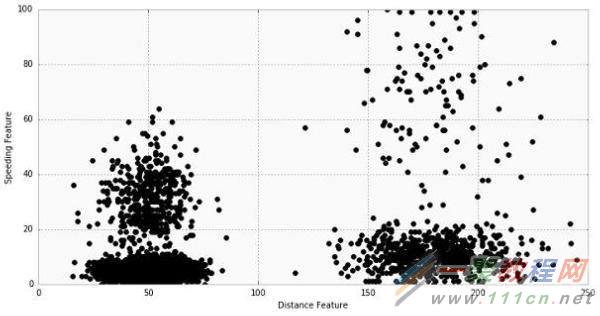
下面的图表显示了4,000个司机的数据集,x轴表示距离特征,y轴表示加速特征。
步骤2: 选择K并运行该算法
首先选择K=2。对于本例,使用Python包scikit-learn和NumPy进行计算,如下所示:
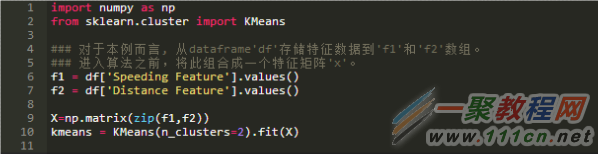
类别标记以kmeans.labels_返回。
步骤3:审查结果
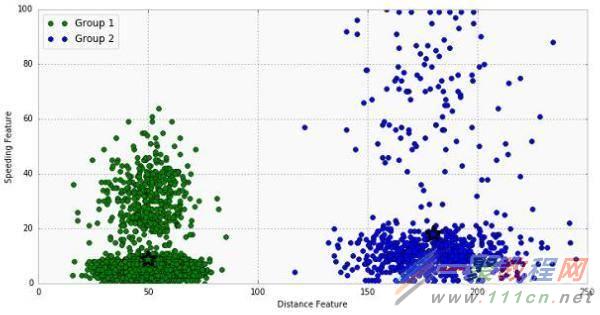
结果如下所示。你可以看到K-means算法基于距离特征分成两组。每个聚类质心用一颗星标记。
-
组1的质心 = (49.62, 8.72)
-
组2的质心 = (179.73, 17.95)
使用数据集的领域知识,我们可以推断组1是都市司机,组2是乡村司机。
步骤4: 对K的多个值迭代
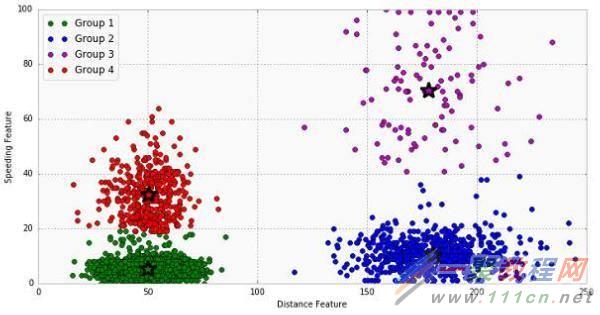
测试K=4的结果。完成这个,你只需要的改变是KMeans()函数中聚类的目标数量。

下面的图表显示了聚类的结果。我们看到由该算法确定了四个不同的组;现在超速驾驶的司机已经与那些遵守速度限制的分开,除了乡村和都市的差别。城市驾驶组比农村司机的速度门槛较
低,可能是由于城市司机在交叉路口和停车交通上花费更多的时间。
附加说明和备选方案
特征工程
特征工程是使用领域知识选择哪些数据度量作为特征输入到机器学习算法的过程。特征工程在K-means聚类中起着关键作用;使用有意义的特征捕获数据的可变性至关重要,针对算法找出所有自然产生的组。
分类数据(例如,分类标志如性别,国家,浏览器类型)需要被编码或者以一种仍然可以使用该算法的方式分离数据。
特征变换,特别是代表利率而不是测量,可以帮助规范化数据。例如,在上面交付车队的例子中,如果使用总驾驶距离而不是每天平均距离,那么驾驶员通过他们在公司驾驶多久而不是乡村和都市的分组。
备选方案
有很多可供替代的聚类算法存在,包括DBScan,谱聚类,和高斯混合建模。维数约减技术,如主成分分析,可以用于数据中的不同组模式。一种可能的结果是数据中没有有机聚类;相反,所
有的数据沿着一个单一组的连续特征范围。既然这样,你可能需要重新查看数据特征以查看是否需要包括不同的测量或者特征变换将更好地代表数据的可变性。此外,你可能想强加分类或者
基于知识领域标记并修改你的分析方法。
相关文章
- 《弓箭传说2》新手玩法介绍 01-16
- 《地下城与勇士:起源》断桥烟雨多买多送活动内容一览 01-16
- 《差不多高手》醉拳龙技能特点分享 01-16
- 《鬼谷八荒》毕方尾羽解除限制道具推荐 01-16
- 《地下城与勇士:起源》阿拉德首次迎新春活动内容一览 01-16
- 《差不多高手》情圣技能特点分享 01-16