



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Python创建属于自己的IP池代码示例
时间:2022-06-25 01:16:47 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下Python创建属于自己的IP池代码示例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
开发环境
Python 3.8
Pycharm
模块使用
requests >>> pip install requests
parsel >>> pip install parsel
如果安装python第三方模块
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
在pycharm中点击Terminal(终端) 输入安装命令
如何配置pycharm里面的python解释器
选择file(文件) >>> setting(设置) >>> Project(项目) >>> python interpreter(python解释器)
点击齿轮, 选择add
添加python安装路径
pycharm如何安装插件
选择file(文件) >>> setting(设置) >>> Plugins(插件)
点击 Marketplace 输入想要安装的插件名字 比如:翻译插件 输入 translation / 汉化插件 输入 Chinese
选择相应的插件点击 install(安装) 即可
安装成功之后 是会弹出 重启pycharm的选项 点击确定, 重启即可生效
代理ip结构
proxies_dict = {
"http": "http://" + ip:端口,
"https": "http://" + ip:端口,
}
思路
一. 数据来源分析
找我们想要数据内容, 从哪里来的
二. 代码实现步骤
发送请求, 对于目标网址发送请求
获取数据, 获取服务器返回响应数据(网页源代码)
解析数据, 提取我们想要的数据内容
保存数据, 爬音乐 视频 本地csv 数据库… IP检测, 检测IP代理是否可用 可用用IP代理 保存
from 从
import 导入
从 什么模块里面 导入 什么方法
from xxx import * # 导入所有方法
代码
# 导入数据请求模块
import requests # 数据请求模块 第三方模块 pip install requests
# 导入 正则表达式模块
import re # 内置模块
# 导入数据解析模块
import parsel # 数据解析模块 第三方模块 pip install parsel >>> 这个是scrapy框架核心组件
lis = []
lis_1 = []
# 1. 发送请求, 对于目标网址发送请求 https://www.k*uai**daili.com/free/
for page in range(11, 21):
url = f'https://www.k*uai**daili.com/free/inha/{page}/' # 确定请求url地址
"""
headers 请求头 作用伪装python代码
"""
# 用requests模块里面get 方法 对于url地址发送请求, 最后用response变量接收返回数据
response = requests.get(url)
# 请求之后返回response响应对象, 200状态码表示请求成功
# 2. 获取数据, 获取服务器返回响应数据(网页源代码) response.text 获取响应体文本数据
# print(response.text)
# 3. 解析数据, 提取我们想要的数据内容
"""
解析数据方式方法:
正则: 可以直接提取字符串数据内容
需要把获取下来html字符串数据 进行转换
xpath: 根据标签节点 提取数据内容
css选择器: 根据标签属性提取数据内容
哪一种方面用那种, 那是喜欢用那种
"""
# 正则表达式提取数据内容
"""
# 正则提取数据 re.findall() 调用模块里面的方法
# 正则 遇事不决 .*? 可以匹配任意字符(除了换行符n以外) re.S
ip_list = re.findall('(.*?) ', response.text, re.S)
port_list = re.findall('(.*?) ', response.text, re.S)
print(ip_list)
print(port_list)
"""
# css选择器:
"""
# css选择器提取数据 需要把获取下来html字符串数据(response.text) 进行转换
# 我不会css 或者 xpath 怎么办
# #list > table > tbody > tr > td:nth-child(1)
# //*[@id="list"]/table/tbody/tr/td[1]
selector = parsel.Selector(response.text) # 把html 字符串数据转成 selector 对象
ip_list = selector.css('#list tbody tr td:nth-child(1)::text').getall()
port_list = selector.css('#list tbody tr td:nth-child(2)::text').getall()
print(ip_list)
print(port_list)
"""
# xpath 提取数据
selector = parsel.Selector(response.text) # 把html 字符串数据转成 selector 对象
ip_list = selector.xpath('//*[@id="list"]/table/tbody/tr/td[1]/text()').getall()
port_list = selector.xpath('//*[@id="list"]/table/tbody/tr/td[2]/text()').getall()
# print(ip_list)
# print(port_list)
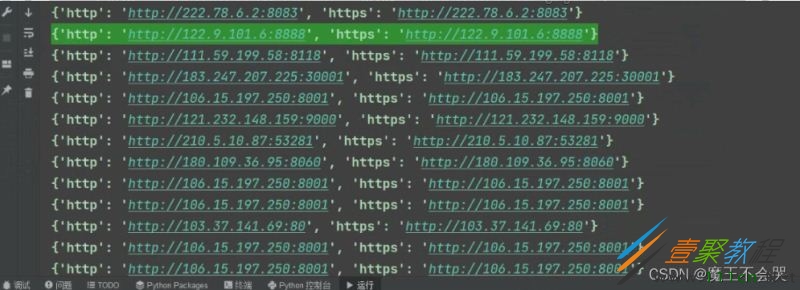
for ip, port in zip(ip_list, port_list):
# print(ip, port)
proxy = ip + ':' + port
proxies_dict = {
"http": "http://" + proxy,
"https": "http://" + proxy,
}
# print(proxies_dict)
lis.append(proxies_dict)
# 4.检测IP质量
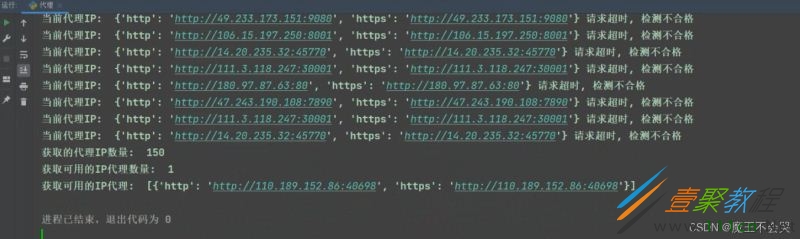
try:
response = requests.get(url=url, proxies=proxies_dict, timeout=1)
if response.status_code == 200:
print('当前代理IP: ', proxies_dict, '可以使用')
lis_1.append(proxies_dict)
except:
print('当前代理IP: ', proxies_dict, '请求超时, 检测不合格')
print('获取的代理IP数量: ', len(lis))
print('获取可用的IP代理数量: ', len(lis_1))
print('获取可用的IP代理: ', lis_1)
dit = {
'http': 'http://110.189.152.86:40698',
'https': 'http://110.189.152.86:40698'
}
相关文章
- 极空间如何进行文件批量重命名 03-31
- 鸣潮爱弥斯值得培养吗 爱弥斯配队声骸推荐 03-31
- 羞羞漫画观看入口在哪-最新官网地址及快速进入方式说明 03-31
- 羞羞漫画-极速登录入口 03-31
- 三国百将牌鲁肃有什么技能 鲁肃豪富技能强度解析 03-31
- 镭明闪击榴弹系统怎么玩 榴弹系统玩法介绍 03-31