



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
TensorFlow卷积神经网络AlexNet实现代码示例
时间:2022-06-25 01:36:54 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下TensorFlow卷积神经网络AlexNet实现代码示例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
2012年,Hinton的学生Alex Krizhevsky提出了深度卷积神经网络模型AlexNet,它可以算是LeNet的一种更深更宽的版本。AlexNet以显著的优势赢得了竞争激烈的ILSVRC 2012比赛,top-5的错误率降低至了16.4%,远远领先第二名的26.2%的成绩。AlexNet的出现意义非常重大,它证明了CNN在复杂模型下的有效性,而且使用GPU使得训练在可接受的时间范围内得到结果,让CNN和GPU都大火了一把。AlexNet可以说是神经网络在低谷期后的第一次发声,确立了深度学习(深度卷积网络)在计算机视觉的统治地位,同时也推动了深度学习在语音识别、自然语言处理、强化学习等领域的拓展。
模型结构见下图:
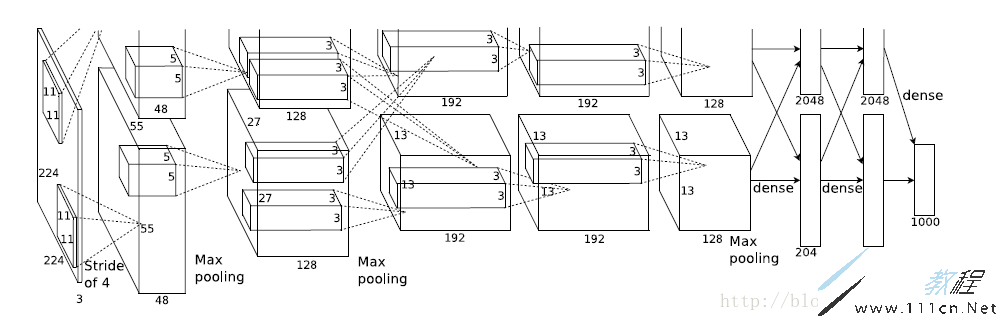
整个AlexNet前5层为卷积层,后3个为全连接层,其中最后一层是1000类输出的Softmax分类输出层。LRN层在第1个及第2个卷积层之后,Max pooling层在两个LRN层之后和最后一个卷积层之后。ReLU激活函数跟在5个卷积层和2个全连接层后面(最后输出层没有)。
因为AlexNet训练时使用了两块GPU,因此这个结构图中不少组件都被拆为了两部分。现在我们GPU的显存足够大可以放下全部模型参数,因此只考虑一块GPU的情况。
AlexNet中包含的新技术点如下:
成功使用ReLU作为CNN的激活函数,并验证了在较深的网络中其效果超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度消失问题。虽然ReLU在很久之前就被提出来了,但AlexNet的出现才将其发扬光大。
网络中加入了Dropout层,训练时使用Dropout随机杀死(忽略)一部分神经元,以避免模型过拟合。(AlexNet通过实践证实了Dropout的效果,关于Dropout有单独的论文论述。)
池化层使用Max pooling,此前CNN普遍使用平均池化,最大池化避免了平均池化的模糊化效果。且提出让步长小于池化核的尺寸,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
提出了LRN层(Local Response Normalization),对局部神经元的活动创建竞争机制,使得其中响应比较大的值变的相对更大,并抑制其它反馈较小的神经元,增强了模型的泛化能力。
使用CUDA加速深度神经网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。(当时Alex使用的是两块GTX 580,单个GPU只有3GB显存,限制了可训练的网络的最大规模。因此他将AlexNet分布在两个GPU上,每个GPU的显存中储存一半的神经元的参数。现在GTX 1080Ti都出来了,硬件发展的还是比较快的,这也是深度学习能飞速发展的重要原因之一吧)
数据增强。随机地从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了((256-224)^2)*2=2048倍的数据量。如果没有数据增强,仅靠原始数据的数据量,参数众多的CNN会陷入过拟合中,进行数据增强后可以大大减轻过拟合,提升模型的泛化能力。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10个图片,对它们进行预测并对求10次结果求均值。同时,AlexNet论文中提到了会对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加了一些噪声,这个Trick可以让错误率再下降1%。
AlexNet每层的超参数如图所示:
其中,
Input:图片尺寸224*224
Conv1:卷积核11*11,步长4,96个filter(卷积核尺寸较大)
ReLU
LRN1
Max pooling1:3*3,步长2
Conv2:卷积核5*5,步长1,256个filter
ReLU
LRN2
Max pooling2:3*3,步长2
Conv3:卷积核3*3,步长1,384个filter
ReLU
Conv4:卷积核3*3,步长1,384个filter
ReLU
Conv5:卷积核3*3,步长1,256个filter
ReLU
Max pooling3:3*3,步长2
FC1:4096
ReLU
FC2:4096
ReLU
FC3(Output):1000
现在对AlexNet使用MNIST数据集,代码如下:
from datetime import datetime
import time
import tensorflow as tf
import input_data
mnist = input_data.read_data_sets('data/', one_hot=True)
print("MNIST READY")
# 定义网络参数
n_input = 784 # 输入的维度
n_output = 10 # 标签的维度
learning_rate = 0.001
dropout = 0.75
# 定义函数print_activations来显示网络每一层结构,展示每一个卷积层或池化层输出tensor的尺寸
def print_activations(t):
print(t.op.name, '', t.get_shape().as_list())
# 定义卷积操作
def conv2d(input, w, b):
return tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(input, w, strides=[1, 1, 1, 1], padding='SAME'), b)) # 参数分别指定了卷积核的尺寸、多少个channel、filter的个数即产生特征图的个数 # 步长为1,即扫描全图像素,[1, 1, 1, 1]分别代表batch_size、h、w、c的stride
# 定义池化操作
def max_pool(input):
return tf.nn.max_pool(input, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # padding有两种选择:'SAME'(窗口滑动时,像素不够会自动补0)或'VALID'(不够就跳过)两种选择
# 定义全连接操作
def fc(input, w, b):
return tf.nn.relu(tf.add(tf.matmul(input, w), b)) # w*x+b,再通过非线性激活函数relu
# 定义网络结构
def alex_net(_input, _weights, _biases, _keep_prob):
_input_r = tf.reshape(_input, [-1, 28, 28, 1]) # 对图像做一个预处理,转换为tf支持的格式,即[n, h, w, c],-1是确定好其它3维后,让tf去推断剩下的1维
with tf.name_scope('conv1'):
_conv1 = conv2d(_input_r, _weights['wc1'], _biases['bc1'])
print_activations(_conv1) # 将这一层最后输出的tensor conv1的结构打印出来
# # 这里参数基本都是AlexNet论文中的推荐值,但目前其他经典卷积神经网络模型基本都放弃了LRN(主要是效果不明显),
# # 并且使用LRN也会让前馈、反馈的速度大大下降(整体速度降到1/3)
# with tf.name_scope('_lrn1'):
# _lrn1 = tf.nn.lrn(_conv1, 4, bias=1.0, alpha=0.001/9, beta=0.75)
with tf.name_scope('pool1'):
_pool1 = max_pool(_conv1)
print_activations(_pool1)
with tf.name_scope('conv2'):
_conv2 = conv2d(_pool1, _weights['wc2'], _biases['bc2'])
print_activations(_conv2)
# with tf.name_scope('_lrn2'):
# _lrn2 = tf.nn.lrn(_conv2, 4, bias=1.0, alpha=0.001/9, beta=0.75)
with tf.name_scope('pool2'):
_pool2 = max_pool(_conv2)
print_activations(_pool2)
with tf.name_scope('conv3'):
_conv3 = conv2d(_pool2, _weights['wc3'], _biases['bc3'])
print_activations(_conv3)
with tf.name_scope('conv4'):
_conv4 = conv2d(_conv3, _weights['wc4'], _biases['bc4'])
print_activations(_conv4)
with tf.name_scope('conv5'):
_conv5 = conv2d(_conv4, _weights['wc5'], _biases['bc5'])
print_activations(_conv5)
with tf.name_scope('pool3'):
_pool3 = max_pool(_conv5)
print_activations(_pool3)
_densel = tf.reshape(_pool3, [-1, _weights['wd1'].get_shape().as_list()[0]]) # 定义全连接层的输入,把pool2的输出做一个reshape,变为向量的形式
# pool_shape = _pool3.get_shape().as_list()
# nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
with tf.name_scope('fc1'):
_fc1 = fc(_densel, _weights['wd1'], _biases['bd1'])
_fc1_drop = tf.nn.dropout(_fc1, _keep_prob) # 为了减轻过拟合,使用Dropout层
print_activations(_fc1_drop)
with tf.name_scope('fc2'):
_fc2 = fc(_fc1_drop, _weights['wd2'], _biases['bd2'])
_fc2_drop = tf.nn.dropout(_fc2, _keep_prob)
print_activations(_fc2_drop)
with tf.name_scope('out'):
_out = tf.add(tf.matmul(_fc2_drop, _weights['wd3']), _biases['bd3'])
print_activations(_out)
return _out
print("CNN READY")
x = tf.placeholder(tf.float32, [None, n_input]) # 用placeholder先占地方,样本个数不确定为None
y = tf.placeholder(tf.float32, [None, n_output]) # 用placeholder先占地方,样本个数不确定为None
keep_prob = tf.placeholder(tf.float32)
# 存储所有的网络参数
weights = {
# 使用截断的正态分布(标准差0.1)初始化卷积核的参数kernel,卷积核大小为3*3,channel为1,个数64
'wc1': tf.Variable(tf.truncated_normal([3, 3, 1, 64], dtype=tf.float32, stddev=0.1), name='weights1'),
'wc2': tf.Variable(tf.truncated_normal([3, 3, 64, 128], dtype=tf.float32, stddev=0.1), name='weights2'),
'wc3': tf.Variable(tf.truncated_normal([3, 3, 128, 256], dtype=tf.float32, stddev=0.1), name='weights3'),
'wc4': tf.Variable(tf.truncated_normal([3, 3, 256, 256], dtype=tf.float32, stddev=0.1), name='weights4'),
'wc5': tf.Variable(tf.truncated_normal([3, 3, 256, 128], dtype=tf.float32, stddev=0.1), name='weights5'),
'wd1': tf.Variable(tf.truncated_normal([4*4*128, 1024], dtype=tf.float32, stddev=0.1), name='weights_fc1'),
'wd2': tf.Variable(tf.random_normal([1024, 1024], dtype=tf.float32, stddev=0.1), name='weights_fc2'),
'wd3': tf.Variable(tf.random_normal([1024, n_output], dtype=tf.float32, stddev=0.1), name='weights_output')
}
biases = {
'bc1': tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32), trainable=True, name='biases1'),
'bc2': tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32), trainable=True, name='biases2'),
'bc3': tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases3'),
'bc4': tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases4'),
'bc5': tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32), trainable=True, name='biases5'),
'bd1': tf.Variable(tf.constant(0.0, shape=[1024], dtype=tf.float32), trainable=True, name='biases_fc1'),
'bd2': tf.Variable(tf.constant(0.0, shape=[1024], dtype=tf.float32), trainable=True, name='biases_fc2'),
'bd3': tf.Variable(tf.constant(0.0, shape=[n_output], dtype=tf.float32), trainable=True, name='biases_output')
}
pred = alex_net(x, weights, biases, keep_prob) # 前向传播的预测值
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) # 交叉熵损失函数,参数分别为预测值_pred和实际label值y,reduce_mean为求平均loss
optm = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # 梯度下降优化器
corr = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1)) # tf.equal()对比预测值的索引和实际label的索引是否一样,一样返回True,不一样返回False
accuracy = tf.reduce_mean(tf.cast(corr, tf.float32)) # 将pred即True或False转换为1或0,并对所有的判断结果求均值
# 初始化所有参数
init = tf.global_variables_initializer()
print("FUNCTIONS READY")
# 上面神经网络结构定义好之后,下面定义一些超参数
training_epochs = 1000 # 所有样本迭代1000次
batch_size = 1 # 每进行一次迭代选择50个样本
display_step = 10
sess = tf.Session() # 定义一个Session
sess.run(init) # 在sess里run一下初始化操作
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
start_time = time.time()
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # 逐个batch的去取数据
# 获取批数据
sess.run(optm, feed_dict={x: batch_xs, y: batch_ys, keep_prob:dropout})
avg_cost += sess.run(cost, feed_dict={x: batch_xs, y: batch_ys, keep_prob:1.0})/total_batch
if epoch % display_step == 0:
train_accuracy = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.0})
test_accuracy = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels, keep_prob:1.0})
print("Epoch: %03d/%03d cost: %.9f TRAIN ACCURACY: %.3f TEST ACCURACY: %.3f" % (epoch, training_epochs, avg_cost, train_accuracy, test_accuracy))
# 计算每轮迭代的平均耗时mn和标准差sd,并显示
duration = time.time() - start_time
print('%s: step %d, duration = %.3f' % (datetime.now(), epoch, duration))
print("DONE")