



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
python批量生成身份证号到Excel两种方法代码实例
时间:2022-11-14 23:01:49 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下python批量生成身份证号到Excel两种方法代码实例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
身份证号码的编排规则
前1、2位数字表示:所在省份的代码;
第3、4位数字表示:所在城市的代码;
第5、6位数字表示:所在区县的代码;
第7~14位数字表示:出生年、月、日;
第15、16位数字表示:所在地的派出所的代码;
第17位数字表示性别:奇数表示男性,偶数表示女性;
第18位数字是校检码,计算方法如下:
(1)将前面的身份证号码17位数分别乘以不同的系数。从第一位到第十七位的系数分别为:7-9-10-5-8-4-2-1-6-3-7-9-10-5-8-4-2。
(2)将这17位数字和系数相乘的结果相加。
(3)用加出来和除以11,取余数。
(4)余数只可能有0-1-2-3-4-5-6-7-8-9-10这11个数字。其分别对应的最后一位身份证的号码为1-0-X -9-8-7-6-5-4-3-2。(即余数0对应1,余数1对应0,余数2对应X…)
第一种方法:网页爬取身份证前六位
import urllib.request
from bs4 import BeautifulSoup
import re
import random
import time
import xlwt
# 通过爬取网页获取到身份证前六位
url = 'http://www.qucha.net/shenfenzheng/city.htm'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'
}
request = urllib.request.Request(url, headers=headers) # 获取url的网页源码
response = urllib.request.urlopen(request)
html = response.read()
soup = BeautifulSoup(html, 'lxml')
strarr = []
for info in soup.find_all('td', valign='top'): #
第二种方法:身份证前六位从本地excel中取
如果自己有这么一份全国身份证前六位的数据且存在excel中,可以直接跳到第二步。没有的话,下面是爬取全国身份证前六位,并保存到自己本地的代码实现,建议跑一遍保存下来,谁知道这个爬取的地址哪天作者删除文件了呢,到时第一种方法就不适用了,得换地址处理等。(另外,爬取下来到excel中自己还能再处理一下前六位,因为我这个爬取包括“440000 广东省”这种,不知道身份证有没有前六位是这种的,我知道的好像没有,我爬下来的前六位没有删掉这些,如下图红框)

# 通过爬取网页获取到身份证前六位并保存到本地excel中
import urllib.request
from bs4 import BeautifulSoup
import re
import xlwt
# 通过爬取网页获取到身份证前六位
url = 'http://www.qucha.net/shenfenzheng/city.htm'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'
}
request = urllib.request.Request(url, headers=headers) # 获取url的网页源码
response = urllib.request.urlopen(request)
html = response.read()
soup = BeautifulSoup(html, 'lxml')
strarr = []
for info in soup.find_all('td', valign='top'): #
导入本地excel数据(身份证前六位)保存为字符串数组,然后生成身份证号码
import random
import time
import xlwt
import pandas as pd
# 不把第1行作为列名,读取Excel那就没有列名,需增加参数:header=None
# 第一个参数为身份证前六位的excel数据路径
df = pd.read_excel('E:CodePythonID_pre_six.xlsx', sheet_name='ID_pre_six', header=None)
# 获取最大行
nrows = df.shape[0]
pre = []
for iRow in range(nrows):
# 将表中第一列数据写入pre数组中
pre.append(df.iloc[iRow, 0])
def year():
'''生成年份'''
# 从1960开始算,now-18直接过滤掉小于18岁出生的年份
now = time.strftime('%Y')
second = random.randint(1960, int(now) - 18)
return second
def month():
'''生成月份'''
three = str(random.randint(1, 12))
mon = three.zfill(2)# zfill() 方法返回指定长度的字符串,原字符串右对齐,前面填充0
return mon
def day(year, month):
'''生成日期'''
four = str(getDay(year, month))
days = four.zfill(2)
return days
def getDay(year, month):
'''根据传来的年月份返回日期'''
# 1,3,5,7,8,10,12月为31天,4,6,9,11为30天,2月闰年为28天,其余为29天
aday = 0
if month in (1, 3, 5, 7, 8, 10, 12):
aday = random.randint(1, 31)
elif month in (4, 6, 9, 11):
aday = random.randint(1, 30)
else:
# 即为2月判断是否为闰年
if ((year % 4 == 0 and year % 100 != 0) or (year % 400 == 0)):
aday = random.randint(1, 28)
else:
aday = random.randint(1, 29)
return aday
def randoms():
'''生成身份证后三位'''
ran = str(random.randint(1, 999))
five = ran.zfill(3)
return five
# 前17位身份证
def ID():
first = random.choice(pre)
second = year()
three = month()
four = day(second, three)
five = randoms()
# 前17位身份证
ID = str(first) + str(second) + three + four + five
return ID
def ID_last():
ID_17 = ID()
lid = list(map(int, ID_17)) # 将字符串数组转为int列表
weight = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2] # 权重项
temp = 0
for i in range(17):
temp += lid[i]*weight[i]
checkcode = ['1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2']# 校验码映射
ID_last = checkcode[temp%11]
return ID_last
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding='utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('IDcard')
# 设置单元格宽度
worksheet.col(0).for i in range(100):# 设置生成数量
IDcard = ID() + ID_last()
worksheet.write(i, 0, IDcard)
# 写入excel,参数对应 行, 列, 值
workbook.save('IDcard.xlsx')
# 运行后 会在当前目录生成一个IDcard.xlsx
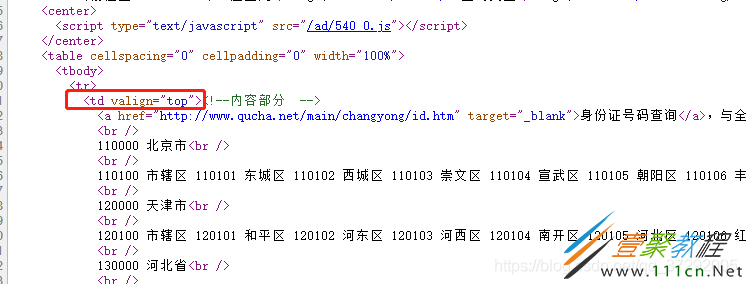
PS:爬取网页中哪个tag里的内容,可以浏览器页面,右键->查看网页源代码,如下图,我需要的内容都含在方框那个tag里:
相关文章
- 《弓箭传说2》新手玩法介绍 01-16
- 《地下城与勇士:起源》断桥烟雨多买多送活动内容一览 01-16
- 《差不多高手》醉拳龙技能特点分享 01-16
- 《鬼谷八荒》毕方尾羽解除限制道具推荐 01-16
- 《地下城与勇士:起源》阿拉德首次迎新春活动内容一览 01-16
- 《差不多高手》情圣技能特点分享 01-16