



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
PHP实现base64编码文件上传出现问题代码解析
时间:2022-06-24 22:20:13 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下PHP实现base64编码文件上传出现问题代码解析,文章介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
一、场景
领导:小A同学,我们要做一个样本上传进行分析的功能,你看下是否使用base64编码加进去,这样客户端的同学就不需要用form-data方式来上传了,直接使用json格式就可以上报,可以让格式上报统一。
小A:好的,领导,马上搞定!
咋看上面的对话没啥问题,很多公司团队内部为了一些标准化的问题,都会进行一些技术选型问题,但是噩梦也就从这个对话开始,功能实现当然都是很简单的,先来看简单流程图:
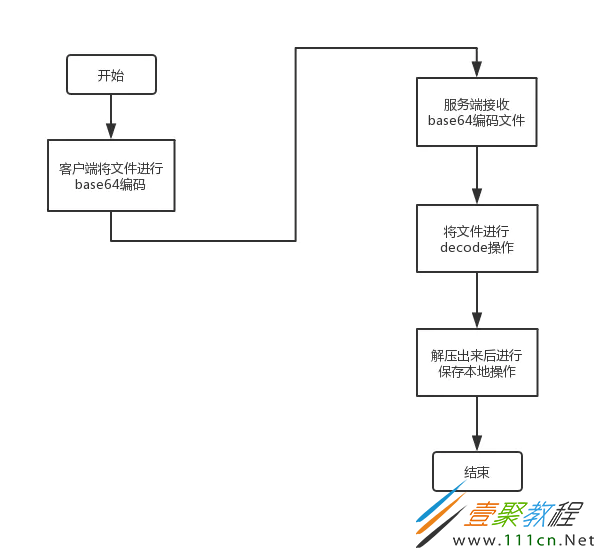
本身的流程是一个很简单的文件转换成base64上传,再服务端decode保存,在开发联调过程中没有问题,非常完美的走下去了。
二、问题来了
突然有一天终端同学误操作将一个37M文件上传,nginx与php-fpm文件上传限制均为(60M),但是在界面出现500错误,进入docker 日志查看有一条数据:
Allowed memory size of 8388608 bytes exhausted (tried to allocate 1298358 bytes)
玩php的基本都知道这是啥意思,就是代码运行过程中使用内存超过 我们php.ini设置的memory_pmit 的值,然后就屁颠屁颠进入php.ini找参数配置,很快找到:
memory_pmit=128M
然后就转念一想,不应该出现这个问题,我们知道,php的内部变量使用cow(写时复制)机制来实现,那么内存申请只有在变量赋值变更才会进行
三、测验
接下来我们单独写一个程序来进行测试,将一个4.89M文件进行base64_encode 编码 与base64_decode解码,查看各自占用内存以及过程中占用峰值内存
执行结果:
string(29) "文件加载到内存:4.89M"
string(38) "过程中峰值使用的内存:5.25M"
string(33) "base64_encode占用内存:1.63M"
string(39) "过程中峰值使用的内存:11.76M"
string(30) "base64_decode占用内存:0M"
string(38) "过程中峰值使用的内存:13.4M"
通过上面结果可以看出
加载文件使用内存没有太大问题,加载过程使用的峰值在5.25M,高出整体文件大小不多,这在文件加载过程有一些临时申请内存的问题
base64_encode占用内存,这个在使用的时候,就已经将内存差不多进行一个double,而这基本上也是在内核解析过程中,进行了内存申请,可以理解,文件本身占用内存+base64_encode 解析后的内存,两份内存同时存在的
base64_decode操作,这个操作就是解密了,解密过程中,这里直接就占用了3倍多的内存操作,问题就出在这里,在场景中出现的问题是一个37M的文件,为什么就把单个fpm的128M内存占满了呢
四、源码解析
base64_encode源码解析
首先找到对应的c文件 base64.c,找到里面php_base64_encode函数
PHPAPI zend_string *php_base64_encode(const unsigned char *str, size_t length) /* {{{ */ { const unsigned char *current = str; unsigned char *p; zend_string *result; result = zend_string_safe_alloc(((length + 2) / 3), 4 * sizeof(char), 0, 0); p = (unsigned char *)ZSTR_VAL(result); ... }我们先来分析这段代码,因为这里涉及到内存的问题,那么我们就看
result = zend_string_safe_alloc(((length + 2) / 3), 4 * sizeof(char), 0, 0);
这啥意思呢?
申请内存,最终调用的函数是:
safe_emalloc(size_t nmemb, size_t size, size_t offset)
在wiki上解释是:
void *safe_emalloc(size_t nmemb, size_t size, size_t offset)分配缓冲区来存放每块大小为size字节的nmemb块,并附加offset字节。类似于emalloc(nmemb * size + offset),但增加了针对溢出的特殊保护。
那么我可以简单的认为,就是在encode过程中,重新申请了内存,申请的内存大小是文件本身的 4/3 大小,加上原来的文件本身大小,那么峰值大小可以理解为
峰值内存= 7/3 *4.89 = 11.41
那么与我们实验过程中峰值大小基本是相符。
base64_decode操作
同样我们进行源码分析
PHPAPI zend_string *php_base64_decode_ex(const unsigned char *str, size_t length, zend_bool strict) /* {{{ */ { const unsigned char *current = str; int ch, i = 0, j = 0, padding = 0; zend_string *result; result = zend_string_alloc(length, 0); ... }这里使用的zend_string_alloc来进行申请内存,那么底层使用的函数就是emalloc函数,来看下wiki的解释
void *emalloc(size_t size)分配size字节的内存。
这个就比较好理解了,传入参数内存再进行一个double拷贝就可以,
那么我们进行一个decode的内存峰值的计算:
峰值内存=(4/3+4/3) *4.89 =13.04
基本与我们测试的结果相差不多,因为精度关系,我们进行四舍五入的计算,测试代码是精准计算,所以会有小数点偏差。
五、总结
那这就可以理解为什么一个为什么在我们一个37M的文件,不能再128M内存进行base64_encode与base64_decode操作,当然这里有一些临时变量没有及时释放内存的情况,但是通过源码分析可以知道,要做一次这样场景来进行文件上传,单纯文件的内存损耗是2.6倍左右,所以为了节省内存,我们不要再用这个方式来进行操作了,很费内存的
相关文章
- 《弓箭传说2》新手玩法介绍 01-16
- 《地下城与勇士:起源》断桥烟雨多买多送活动内容一览 01-16
- 《差不多高手》醉拳龙技能特点分享 01-16
- 《鬼谷八荒》毕方尾羽解除限制道具推荐 01-16
- 《地下城与勇士:起源》阿拉德首次迎新春活动内容一览 01-16
- 《差不多高手》情圣技能特点分享 01-16