



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
java实现word文件转html文件
时间:2022-06-29 01:26:05 编辑:袖梨 来源:一聚教程网
最近在项目开发中用户提出要在电脑上没有装office时在浏览器中打开word文件,最后确定的逻辑:用户选择想要查看的文件,页面js判断文件是否为word。不是执行下载,是后端根据word文件后缀访问对应转换方法。文件已存在对应html文件直接返回html文件地址,不存在先生成对应html文件再返回地址。js直接通过open()打开新的页签,展示word文件内容。新人一枚,如果代码中存在错误或有更好的实现万望指正!
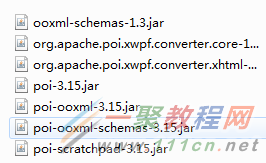
相关jar包
代码
| 代码如下 | 复制代码 |
importjava.io.ByteArrayOutputStream; importjava.io.File; importjava.io.FileInputStream; importjava.io.FileNotFoundException; importjava.io.FileOutputStream; importjava.io.IOException; importjava.io.InputStream; importjava.io.OutputStream;
importjavax.xml.parsers.DocumentBuilderFactory; importjavax.xml.parsers.ParserConfigurationException; importjavax.xml.transform.OutputKeys; importjavax.xml.transform.Transformer; importjavax.xml.transform.TransformerException; importjavax.xml.transform.TransformerFactory; importjavax.xml.transform.dom.DOMSource; importjavax.xml.transform.stream.StreamResult;
importorg.apache.poi.hwpf.HWPFDocument; importorg.apache.poi.hwpf.converter.PicturesManager; importorg.apache.poi.hwpf.converter.WordToHtmlConverter; importorg.apache.poi.hwpf.usermodel.PictureType; importorg.apache.poi.xwpf.converter.core.BasicURIResolver; importorg.apache.poi.xwpf.converter.core.FileImageExtractor; importorg.apache.poi.xwpf.converter.core.FileURIResolver; importorg.apache.poi.xwpf.converter.xhtml.XHTMLConverter; importorg.apache.poi.xwpf.converter.xhtml.XHTMLOptions; importorg.apache.poi.xwpf.usermodel.XWPFDocument; importorg.w3c.dom.Document;
/** * word 转换成html 2017-2-27 */ publicclassWordToHtml {
/** * 将word2003转换为html文件 2017-2-27 * @param wordPath word文件路径 * @param wordName word文件名称无后缀 * @param suffix word文件后缀 * @throws IOException * @throws TransformerException * @throws ParserConfigurationException */ publicString Word2003ToHtml(String wordPath,String wordName,String suffix)throwsIOException, TransformerException, ParserConfigurationException { String htmlPath = wordPath + File.separator + wordName +"_show"+ File.separator; String htmlName = wordName +".html"; finalString imagePath = htmlPath +"image"+ File.separator;
//判断html文件是否存在 File htmlFile =newFile(htmlPath + htmlName); if(htmlFile.exists()){ returnhtmlFile.getAbsolutePath(); }
//原word文档 finalString file = wordPath + File.separator + wordName + suffix; InputStream input =newFileInputStream(newFile(file));
HWPFDocument wordDocument =newHWPFDocument(input); WordToHtmlConverter wordToHtmlConverter =newWordToHtmlConverter(DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument()); //设置图片存放的位置 wordToHtmlConverter.setPicturesManager(newPicturesManager() { publicString savePicture(byte[] content, PictureType pictureType, String suggestedName,floatwidthInches,floatheightInches) { File imgPath =newFile(imagePath); if(!imgPath.exists()){//图片目录不存在则创建 imgPath.mkdirs(); } File file =newFile(imagePath + suggestedName); try{ OutputStream os =newFileOutputStream(file); os.write(content); os.close(); }catch(FileNotFoundException e) { e.printStackTrace(); }catch(IOException e) { e.printStackTrace(); } //图片在html文件上的路径 相对路径 return"image/"+ suggestedName; } });
//解析word文档 wordToHtmlConverter.processDocument(wordDocument); Document htmlDocument = wordToHtmlConverter.getDocument();
//生成html文件上级文件夹 File folder =newFile(htmlPath); if(!folder.exists()){ folder.mkdirs(); }
//生成html文件地址 OutputStream outStream =newFileOutputStream(htmlFile);
DOMSource domSource =newDOMSource(htmlDocument); StreamResult streamResult =newStreamResult(outStream);
TransformerFactory factory = TransformerFactory.newInstance(); Transformer serializer = factory.newTransformer(); serializer.setOutputProperty(OutputKeys.ENCODING,"utf-8"); serializer.setOutputProperty(OutputKeys.INDENT,"yes"); serializer.setOutputProperty(OutputKeys.METHOD,"html");
serializer.transform(domSource, streamResult);
outStream.close();
returnhtmlFile.getAbsolutePath(); }
/** * 2007版本word转换成html 2017-2-27 * @param wordPath word文件路径 * @param wordName word文件名称无后缀 * @param suffix word文件后缀 * @return * @throws IOException */ publicString Word2007ToHtml(String wordPath,String wordName,String suffix)throwsIOException { String htmlPath = wordPath + File.separator + wordName +"_show"+ File.separator; String htmlName = wordName +".html"; String imagePath = htmlPath +"image"+ File.separator;
//判断html文件是否存在 File htmlFile =newFile(htmlPath + htmlName); if(htmlFile.exists()){ returnhtmlFile.getAbsolutePath(); }
//word文件 File wordFile =newFile(wordPath + File.separator + wordName + suffix);
// 1) 加载word文档生成 XWPFDocument对象 InputStream in =newFileInputStream(wordFile); XWPFDocument document =newXWPFDocument(in);
// 2) 解析 XHTML配置 (这里设置IURIResolver来设置图片存放的目录) File imgFolder =newFile(imagePath); XHTMLOptions options = XHTMLOptions.create(); options.setExtractor(newFileImageExtractor(imgFolder)); //html中图片的路径 相对路径 options.URIResolver(newBasicURIResolver("image")); options.setIgnoreStylesIfUnused(false); options.setFragment(true);
// 3) 将 XWPFDocument转换成XHTML //生成html文件上级文件夹 File folder =newFile(htmlPath); if(!folder.exists()){ folder.mkdirs(); } OutputStream out =newFileOutputStream(htmlFile); XHTMLConverter.getInstance().convert(document, out, options);
returnhtmlFile.getAbsolutePath(); } } | |
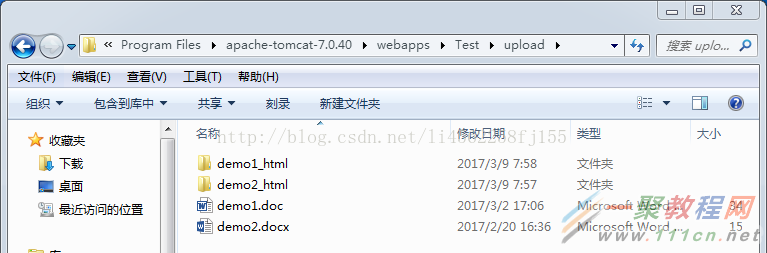
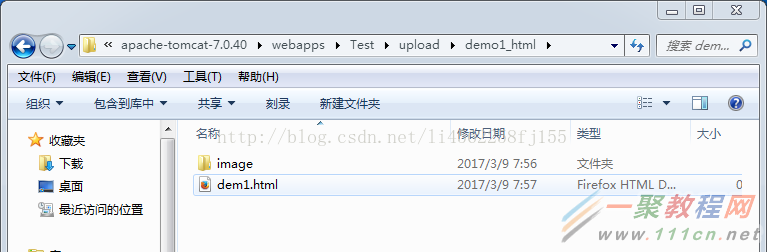
文件目录:
相关文章
- JM漫画官网免费入口-JMComic官网直通车 03-14
- 微博网页版官网入口-微博网页版官方登录 03-14
- 国产在线观看免费视频-国产免费看剧app排行 03-14
- 子豪漫画免费下拉式阅读土豪漫画最新下载入口-子豪漫画免费下拉式观看土豪漫画安装入口 03-14
- 夸克浏览器网页版入口-夸克浏览器网页版官方地址 03-14
- 百度购物频道入口-百度购物频道怎么进入 03-14