



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
从数据存放的角度分析INDEX索引总结
时间:2022-06-29 07:56:06 编辑:袖梨 来源:一聚教程网
测试表结构:
| 代码如下 | 复制代码 |
| CREATE TABLE TB1 ( ID INT IDENTITY(1,1), C1 INT, C2 INT ) | |
1. 聚集索引(Clustered index)
聚集索引可以理解为一个包含表中除索引键外多有剩余列的包含索引,为保证在DELETE/UPDATE操作的正确性,如果聚集索引未声明为唯一(UNIQUE),则系统会聚集索引键增加一个NULLABLE的INT类型标识列(UNIQUIFIER)以保证记录唯一性。
唯一聚集索引:
CREATE UNIQUE CLUSTERED INDEX IDX_ID
ON TB1
(
ID
)

非唯一聚集索引:
CREATE CLUSTERED INDEX IDX_ID
ON TB1
(
ID
)

2. 非唯一非聚集索引
为从非聚集索引定位到数据,对于堆表,非聚集索引会存放索引键+数据的RID(FILE_ID+PAGE_ID+SLOT_ID),对于聚集表,非聚集索引会存放索引键+聚集索引键。
非聚集索引:
CREATE INDEX IDX_C1
ON TB1
(
C1
)

堆表上非聚集索引:
唯一聚集索引表上非聚集索引:

非唯一聚集索引表非聚集索引:

--==============================
后续的测试默认使用唯一聚集索引
--==============================
3. 唯一非聚集索引
唯一非聚集索引与非唯一非聚集索引的区别主要在非叶子节点上,唯一非聚集索引的非叶子节点上不会包含RID的数据。
唯一非聚集索引:
CREATE UNIQUE INDEX IDX_C1_UNI
ON TB1
(
C1
)

4. 包含索引
包含索引在SQL SERVER 2008版本中引入,包含列的数据只存在在叶子节点上。包含列不影响索引行的位置(不会被排序),且包含列不会影响索引键的大小(SQL SERVER 限制索引键不得超过900字节)
复制代码
CREATE INDEX IDX_C1_INC_C2
ON TB1
(
C1
)INCLUDE
(
C2
)

5. 过滤索引
当过滤列不作为索引键或包含列时,系统无需在索引中存放过滤列的数据,因此过滤列不会出现在索引的叶子节点和非叶子节点上。
CREATE INDEX IDX_C1_WH_C2
ON TB1
(
C1
)
WHERE C2>1

--=============================================================
总结&建议:
1. 对于聚集表,由于索引非聚集索引都会包含聚集键,因此建议优先考虑静态+唯一+递增+长度较小的索引键作为索引键
a. 静态:当聚集键被更新时,除了将表数据移动到相应的位置上,依次更新所有的非聚集索引,会消耗大量资源,并导致页拆分和索引碎片
b. 唯一: 非唯一聚集索引增加2至6个字节的消耗,导致聚集索引和非聚集索引消耗更多页面
c. 递增:对于非递增的聚集索引键来说,插入操作会引发页拆分和索引碎片
d. 长度较小:长度较大的聚集索引键同样会导致聚集索引和非聚集索引消耗更多页面,尤其是导致索引层数增加,增加INDEX SEEK的开销。
2. 索引列的可选择性和索引列顺:高选择性不代表该列就适合放在索引前部,还应该考虑针对该列是范围查询还是等值查询,如订单表的创建时间列CreatedTime主要用作范围查询,而订单表的产品编号ProductID主要用等值查询,那么对于
WHERE ProductID=@P1
AND CreatedTime>@P2
AND CreatedTime<@p3
这样的查询,索引 INDEX(ProductID,CreatedTime)就会比INDEX(CreatedTime,ProductID) 更高效(消耗更少的CPU和IO资源)。
3. 索引列顺序与统计:索引列先后顺序不同,其对于的统计信息的密度(density)和直方图(histogram)也不相同,会间接影响到生成的执行计划。
4. 对于选择性较低且位于索引列后端的列来说,可以考虑将其放入到包含索引列中。
5. 虽然过滤索引在统计信息更新方面存在一定的问题,过滤索引依然是解决部分疑难杂症的必杀技(如SELECT TOP(10) * FROM orders WHERE ProductID>10000 ORDER BY OrderID DESC)
6. 在对递增的列建立索引时,应考虑统计过期导致执行计划低效的问题,如对订单表上创建日期列建立索引。
准备测试数据:
| 代码如下 | 复制代码 |
| CREATE TABLE TB1 ( C1 INT, C2 INT, C3 INT ) GO CREATE UNIQUE CLUSTERED INDEX IDX_C1 ON TB1(C1) GO CREATE UNIQUE INDEX IDX_C2 ON TB1(C2) GO CREATE INDEX IDX_C3 ON TB1(C3) GO INSERT INTO TB1(C1,C2,C3)VALUES(1,1,1) GO INSERT INTO TB1(C1,C2,C3)VALUES(2,2,2) GO INSERT INTO TB1(C1,C2,C3)VALUES(3,3,3) | |
索引编号如下:
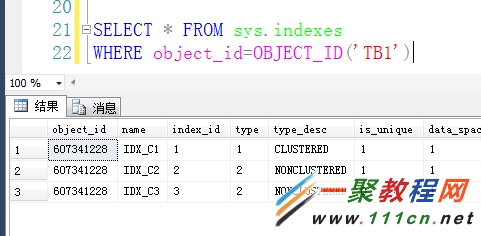
再通过DBCC IND和DBCC PAGE来查看页情况
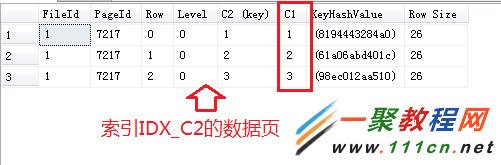
唯一非聚集索引IDX_C2的数据页:
非唯一非聚集索引IDX_C3的数据页:

以上两张图有个明显的区别是C1和C1(key),难道在“非唯一非聚集索引”中,“聚集索引键”也被放到“非聚集索引键”中并且参与排序啦?
相信很多DBA的朋友都遇到这样的问题,要按照某些状态值来查找数据,而这些状态值是一个很小的集合(数量很小),如查找状态值为1的最大订单号
| 代码如下 | 复制代码 |
| SELECT TOP(1)* FROM dbo.Orders WHERE OrderState=1 ORDER BY OrderID DESC | |
虽然OrderID为主键和唯一聚集索引,但按照OrderID来查找,可能需要进行大范围CLUSTERED INDEX SEEK才能找到满足条件OrderState=1的数据,因此尽管OrderState的可选择性较低,我们还是会对其建立索引,那么问题来了?我们索引该建成什么样呢?
是建成:
| 代码如下 | 复制代码 |
CREATE INDEX IDX_OrderState ON dbo.Orders ( OrderState ) | |
还是建成:
CREATE INDEX IDX_OrderState
ON dbo.Orders
(
OrderState,
OrderID
)
曾经我想当然地认为必须建成第二种方式,因为还需要对OrderID进行排序取TOP(1),但经过测试,神奇地发现两种方式的效率一样,无论“非唯一非聚集索引键”里有没有包含“聚集索引键”,都会对“非唯一非聚集索引键”+“聚集索引键”进行排序。
思考这样一个问题,假设对“非唯一非聚集索引键”,仅仅对其定义的键进行排序,如OrderState,而满足OrderState=0的可能有1亿数据,在进行数据更新的时候,首先更新聚集索引,并依次更新非聚集索引,更新索引数据首先要定位数据行才能更新,因此需要扫描这1亿数据才能找到目标行,显然这是不可接受的设计。
对于"唯一非聚集索引"来说,因为可以通过索引键便可以快速定位到索引数据行,且每个键值只会存在一行,因此失去了对“聚集索引键”进行排序的意义。
BTW, 也可以通过观察相同键值下行位置(slotid)和插入顺序来发现数据按照聚集索引键排序。
--===========================================================================
总结:
1. 对于“非唯一非聚集索引”,索引数据实际上是按照“非唯一非聚集索引键”+“聚集索引键”进行排序后存放的;
2. 对于“唯一非聚集索引”,索引数据实际上是按照“唯一非聚集索引键”进行排序后存放的;
3. 所有非聚集索引的叶子节点上都会存放RID的数据,但唯一非聚集索引的非叶子节点上不会包含RID的数据;
--===========================================================================
相关文章
- 《弓箭传说2》新手玩法介绍 01-16
- 《地下城与勇士:起源》断桥烟雨多买多送活动内容一览 01-16
- 《差不多高手》醉拳龙技能特点分享 01-16
- 《鬼谷八荒》毕方尾羽解除限制道具推荐 01-16
- 《地下城与勇士:起源》阿拉德首次迎新春活动内容一览 01-16
- 《差不多高手》情圣技能特点分享 01-16