



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
oracle 利用DMU修改数据库字符集
时间:2022-06-29 09:36:21 编辑:袖梨 来源:一聚教程网
和oracle字符集相关的参数是nls_lang。NLS_LANG的格式是:language_territory.client_charset,如AMERICAN_AMERICA.ZHS16GBK,那么第一位AMERICAN表示语言,第二位AMERICA表示日期和数字格式,第三位ZHS16GBK表示字符集。影响数据库和客户端的其实是第三部分。
通常情况下,数据库字符集不轻易修改,如果要修改,一般可以简单采用下面两种方法可行。:
1. 如果需要修改字符集,通常需要导出数据库数据,重建数据库,再导入数据库数据的方式来转换。
2. 通过ALTER DATABASE CHARACTER SET|[INTERNAL_USE]
另外,我们还可以用csscan/csalter,和DMU(The Database Migration Assistant for Unicode)来实现数据库的字符集转换。
csscan/csalter适用在10g和11.1,在11.2之后就desupport,12c之后,唯一的字符集转换工具就是DMU。我们以DMU为例,进行一次数据集的转换。我们将原来的zhs16gbk的数据库字符集,转成al32utf8的字符集。
DMU的介绍可见The Database Migration Assistant for Unicode (DMU) Tool (Doc ID 1272374.1),且在这个文档中,也说明了可以在这里下载DMU。
初始的情况:
[oracle11g@testdb2 ~]$ env |grep -i lang
LANG=en_US.UTF-8
[oracle11g@testdb2 ~]$
[oracle11g@testdb2 ~]$ export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
[oracle11g@testdb2 ~]$ sqlplus test/test
SQL*Plus: Release 11.2.0.4.0 Production on Mon Jun 20 15:27:58 2016
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, Oracle Label Security, OLAP, Data Mining
and Real Application Testing options
SQL> select * from nls_database_parameters where parameter in ('NLS_LANGUAGE','NLS_TERRITORY','NLS_CHARACTERSET','NLS_NCHAR_CHARACTERSET');
PARAMETER VALUE
------------------------------ ----------------------------------------
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
NLS_CHARACTERSET ZHS16GBK
NLS_NCHAR_CHARACTERSET AL16UTF16
SQL>
SQL> create table cs_test(a varchar2(4));
SQL> insert into cs_test values('1234');
SQL> insert into cs_test values('abcd');
SQL> insert into cs_test values('回家');
SQL> insert into cs_test values('高兴');
SQL> insert into cs_test values('好玩');
SQL> commit;
SQL> select dump(a,1017) from cs_test;
DUMP(A,1017)
--------------------------------------------------------------------------------
Typ=1 Len=4 CharacterSet=ZHS16GBK: 1,2,3,4
Typ=1 Len=4 CharacterSet=ZHS16GBK: a,b,c,d
Typ=1 Len=4 CharacterSet=ZHS16GBK: bb,d8,bc,d2
Typ=1 Len=4 CharacterSet=ZHS16GBK: b8,df,d0,cb
Typ=1 Len=4 CharacterSet=ZHS16GBK: ba,c3,cd,e6
SQL>
SQL> select dump(a,1016) from cs_test;
DUMP(A,1016)
--------------------------------------------------------------------------------
Typ=1 Len=4 CharacterSet=ZHS16GBK: 31,32,33,34
Typ=1 Len=4 CharacterSet=ZHS16GBK: 61,62,63,64
Typ=1 Len=4 CharacterSet=ZHS16GBK: bb,d8,bc,d2
Typ=1 Len=4 CharacterSet=ZHS16GBK: b8,df,d0,cb
Typ=1 Len=4 CharacterSet=ZHS16GBK: ba,c3,cd,e6
SQL> insert into cs_test select * from cs_test;
--插入若干次。变成一张有500多万数据,64M的表。
SQL>commit;
SQL> select segment_name,(bytes)/1024/1024 size_mb from dba_segments where segment_name='CS_TEST';
SEGMENT_NAME SIZE_MB
------------------------------ ----------
CS_TEST 64
SQL> select count(*) from cs_test;
COUNT(*)
----------
5242880
SQL>
--再创建CS_TEST2表,字段类型比CS_TEST的大,是varchar2(20),而不是varchar2(4),然后灌入CS_TEST的数据:
SQL> create table CS_TEST2 (b varchar2(20));
SQL> insert into CS_TEST2 select * from CS_TEST;
SQL> commit;
--再创建CS_TEST3表,也是varchar2(4),一会用bulk cleansing的方式清洗:
SQL> create table CS_TEST3 as select * from CS_TEST;
--在test2下再建立一个clob字段的表,检查看看是否会影响clob字段
SQL> conn test2/test2
Connected.
SQL>
SQL> create table t ( x int, y clob );
SQL> create or replace procedure p( p_x in int, p_new_text in varchar2 )
2 as
3 begin
4 insert into t values ( p_x, p_new_text );
5 end;
6 /
Procedure created.
SQL> exec p(1, rpad('*',32000,'*') );
SQL> exec p(1, rpad('我',32000,'他'));
SQL> exec p(1, rpad('我',32002,'他'));
SQL> exec p(1, rpad('我',32200,'他'));
SQL> select x, dbms_lob.getlength(y) from t;
X DBMS_LOB.GETLENGTH(Y)
---------- ---------------------
1 32000
1 16000
1 16001
1 16100
SQL>
--再建一个cs_test_normal,是char类型。
SQL> create table cs_test_normal as select 'a' as myname from dual connect by level <=100;
Table created.
SQL> desc cs_test_normal
Name Null? Type
----------------------------------------- -------- ----------------------------
MYNAME CHAR(1)
SQL>
下面,我们就用DMU来进行字符集的转换。DMU目前只是提供了GUI界面,没有CLI界面,所以下面我们都用截图表示(每个截图可点击放大)。
注1,使用DMU,必须在数据库中安装XDB组件,不然会报错:
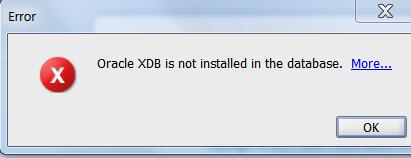
注2,我们需要先运行?/rdbms/admin/prvtdumi.plb,不然会报错如下:
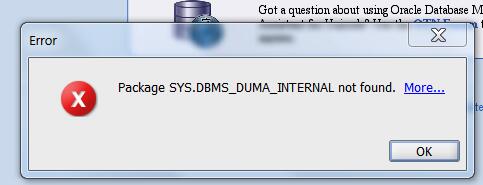
注3,建立存放DMU repository的表空间:
SQL> create tablespace tbs_csmig datafile '/u01/ora11g/app/oracle/oradata/dmutest/csmig.dbf' size 200m autoextend on;
Tablespace created.
SQL>
注4,由于修改字符集是逻辑的修改,可以在备份数据库的情况下,创建一个回滚点,以便在修改失败的情况下,迅速恢复。
SQL> create restore point before_cs_change guarantee flashback database;
Restore point created.
SQL>
好了,完成上述工作后,开始启动dmuW64.exe:
点击新建数据库连接:
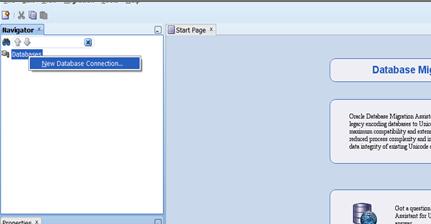
输入数据库连接信息:
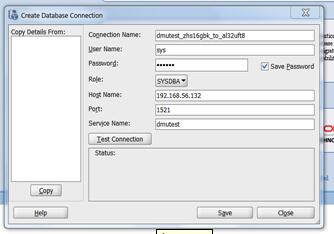
点击test connection,测试连接是否成功。如果成功,显示如下:
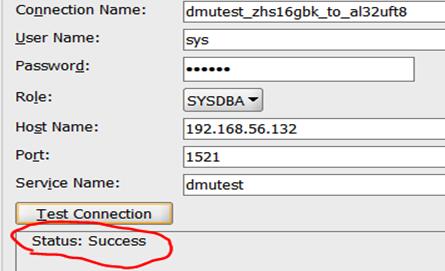
点击connect数据库,连上我们需要修改字符集的数据库。

可以看到原库的字符集,和要求建立repository。
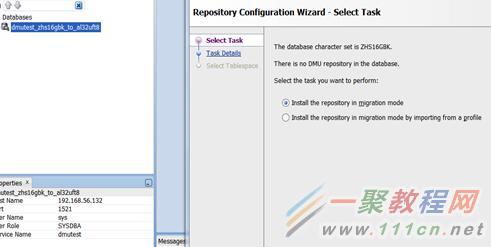
我们转换成建议值,al32utf8。
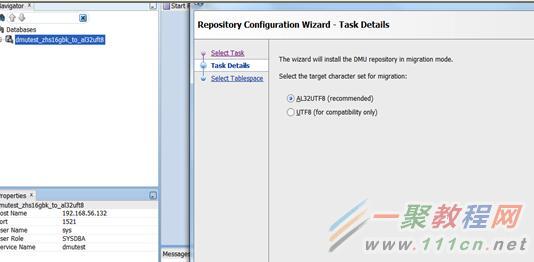
选择之前建立的表空间。
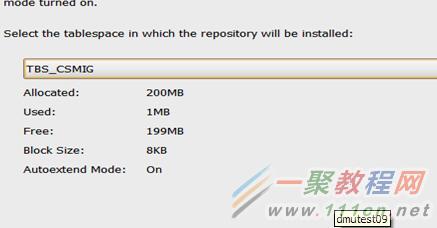
repository建立完成。

出现migration status 主菜单。

点击scan database。

进入scan设置向导。
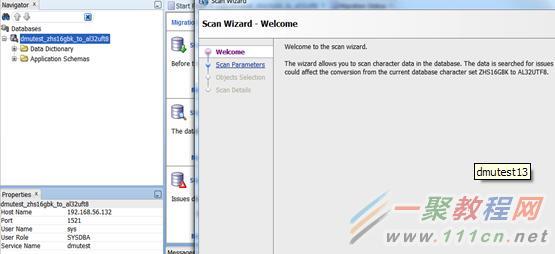
设置scan的进程数和buffer大小。

注意勾上所有的data dict和应用schema。

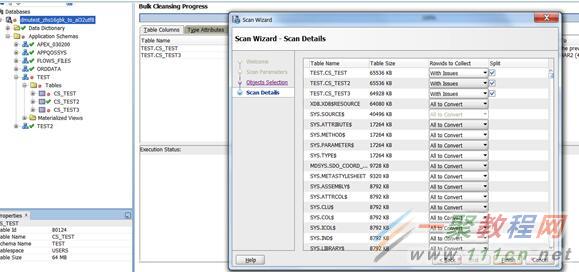
根据设置的进程数,计算表的切割份数。

点击finish开始扫描。

开始扫描了,可以看到扫描进度。

可以看到,如果扫描到有问题的schema,左边会显示一个感叹号。

要查看scan报告,可以点击database scan report。
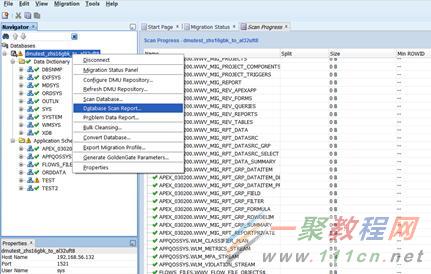
可以点击expand all按钮,显示全部。

我们需要关注with some issues。

expand all之后,可以看到我的cs_test和cs_test3有问题。因为这2个表的a字段都是varchar2(4),里面包含两个汉字的行,zhs16gbk是可以满足的,但是转成al32utf8之后,2个汉字会占据6个字符,varchar2(4)就无法容纳了。在这里,我们对于两个表采用不同的修改方式:第一个表用手工清洗,第二个表我们用bulk cleansing放在批量的方式中处理。

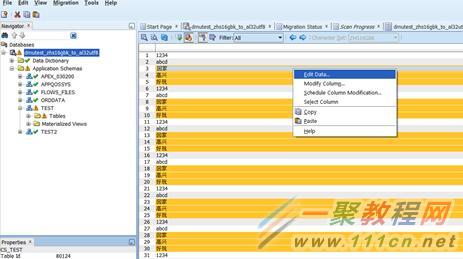
我们开始对第一个表进行手工清洗。点击cleansing editor。

点击edit data。
可以看到转换前后的差别。
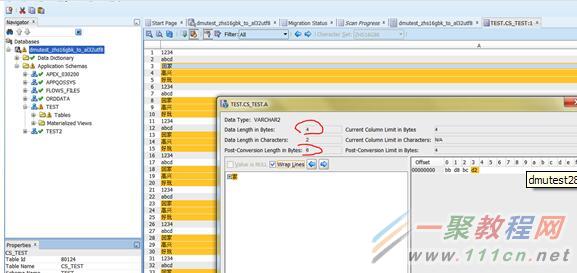
然后我们进行修改,点击schedule的modify,这样就能在最后convert阶段修改,而不是当前就修改了。
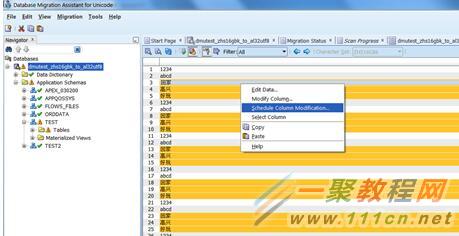
我们把长度改成6,然后点击apply。

可以看到现在都已经变成了绿色。
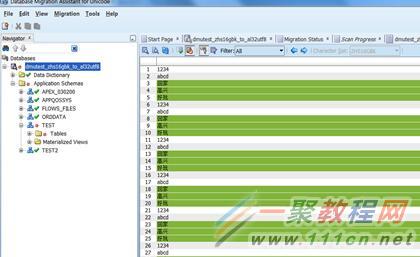
好了,手工清洗的,我只举了一个例子,由于如果很多表需要修改的话,手工清洗会很麻烦,我们可以采用批量清洗的方式。现在我们就点击bulk cleansing,开始批量清洗。
进入批量清洗向导。
选择修改成character length semantics,就原来是varchar2(4),会修改成varchar2(4 char)。即按照实际使用的字符计算。
同样也选择schedule,即在convert阶段进行这些操作。
点击所有红圈和感叹号的对象。
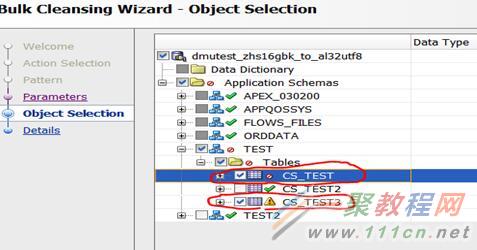
可以看到我们之前的两个表都需要转换。
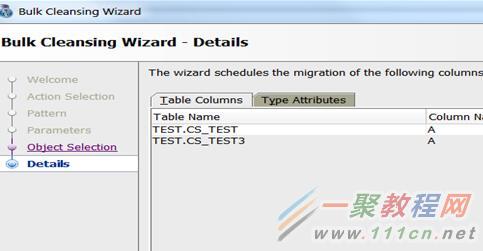
两个表都被列在了计划中。

清洗步骤完成后,再次扫描一次database,确认所有的要素都会在convert时被修复。
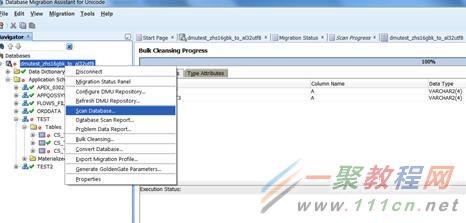
再次进入扫描向导。

再次设置scan的进程数和buffer
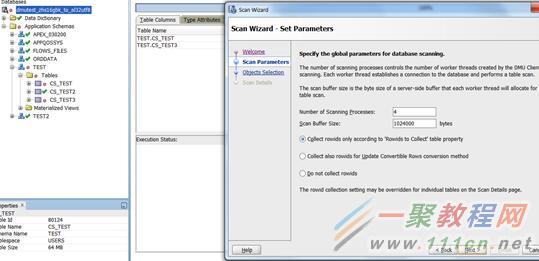
再次勾上所有。

再次点击finish开始扫描
扫描完成,可以看到左右的都是勾。
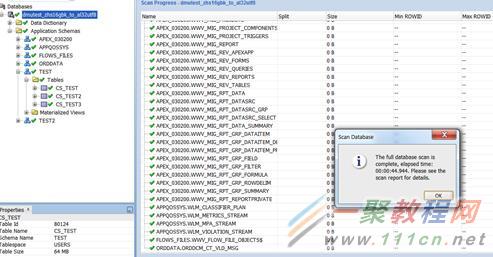
点击convert database开始转换。

请注意看conversion step。列出来了convert的各个步骤,我们看到第一个步骤是修改一些参数和禁用一些trigger。以防止在转换过程中触发内部操作。
第二个步骤是对字段进行内部更新。
第三个步骤暂时没有看到相关操作。
第四步骤,是进行了internal_use的转换。
第五步,是将刚刚bulk cleansing的字段进行修改,并且将在第一步中修改的参数复原。
注意,在右上角,我们可以修改一些convert时的参数。如点击点一个conversion parameters:
我们可以选择并发度(就是第二步的update的语句的并发度),另外还有convert的进程数等等。
对于第二个table convert plan,我们点开,
也可以看到转换的方式。比如选择只需要convert的行进行转换。

选择完之后,回到原来的界面,可以看到第二步的语句中已经有变化,后面多了where的条件。

点击右边中间的convert按钮,开始正式转换。会提示你最后一次scan是什么时间。
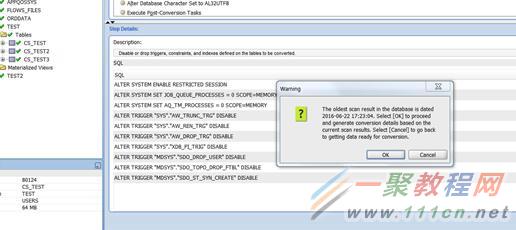
提示你要对数据库进行backup。

转换开始,可以看到右上角正在执行的步骤。
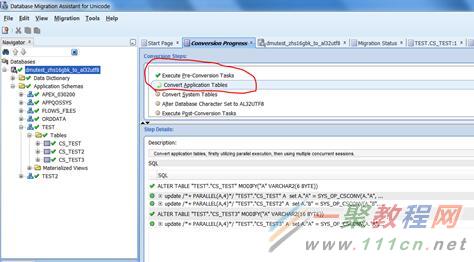
转换结束,要求你断开DMU,重启数据库(因为还在restricted模式)。

转换后:
SQL> select * from nls_database_parameters where parameter in ('NLS_LANGUAGE','NLS_TERRITORY','NLS_CHARACTERSET','NLS_NCHAR_CHARACTERSET');
PARAMETER VALUE
------------------------------ ------------------------------
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
NLS_CHARACTERSET AL32UTF8
NLS_NCHAR_CHARACTERSET AL16UTF16
SQL>
SQL> desc cs_test
Name Null? Type
----------------------------------------------------- -------- ------------------------------------
A VARCHAR2(4 CHAR)
SQL>
SQL> select dump(a,1016) from cs_test where rownum<=4;
DUMP(A,1016)
----------------------------------------------------------------------------------------------------
Typ=1 Len=4 CharacterSet=AL32UTF8: 31,32,33,34
Typ=1 Len=4 CharacterSet=AL32UTF8: 61,62,63,64
Typ=1 Len=6 CharacterSet=AL32UTF8: e5,9b,9e,e5,ae,b6
Typ=1 Len=6 CharacterSet=AL32UTF8: e9,ab,98,e5,85,b4
SQL> select dump(a,1017) from cs_test where rownum<=4;
DUMP(A,1017)
----------------------------------------------------------------------------------------------------
Typ=1 Len=4 CharacterSet=AL32UTF8: 1,2,3,4
Typ=1 Len=4 CharacterSet=AL32UTF8: a,b,c,d
Typ=1 Len=6 CharacterSet=AL32UTF8: e5,9b,9e,e5,ae,b6
Typ=1 Len=6 CharacterSet=AL32UTF8: e9,ab,98,e5,85,b4
SQL>
下面我们来看一下在新数据库中的字符是否显示正确。
注,如果看不到正确的数据,可能和以下因素有关。
(1)客户端操作系统不支持显示中文。
(2)Oracle客户端工具不支持显示中文。
(3)Oracle客户端有相关设置(比如NLS_LANG)不正确。
(4)存储在数据库中的数据已经是不正确的数据。
我的客户端是SecureCRT,操作系统是win7,操作系统支持中文。客户端也支持中文,客户端的nls_lang是继承操作系统,由于下面的设置是default:

所以就继承了OS的编码,操作系统的page code是936,即gbk,所以要设置客户端的nls_lang为gbk。
如果不设置为gbk,就犯了上面的第三条,就会报错。见下。
windows环境字符集:
C:Usersjijihe>chcp
Active code page: 936
即GBK的字符集
而我的SecureCRT由于是设置default是继承操作系统的,所以也是GBK。要正确显示数据库中的字符,需要也设置成gbk
SecureCRT登录数据库后:
[oracle11g@testdb2 ~]$ env |grep -i lang
LANG=en_US.UTF-8
[oracle11g@testdb2 ~]$
[oracle11g@testdb2 ~]$ 如果设置成al32utf8,此时就会乱码:
[oracle11g@testdb2 ~]$ export NLS_LANG=american_america.al32utf8
[oracle11g@testdb2 ~]$
[oracle11g@testdb2 ~]$
[oracle11g@testdb2 ~]$ sqlplus "/ as sysdba"
SQL*Plus: Release 11.2.0.4.0 Production on Wed Jun 22 18:12:18 2016
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, Oracle Label Security, OLAP, Data Mining
and Real Application Testing options
SQL> select * from nls_database_parameters where parameter in ('NLS_LANGUAGE','NLS_TERRITORY','NLS_CHARACTERSET','NLS_NCHAR_CHARACTERSET')
SQL> /
PARAMETER VALUE
------------------------------ ------------------------------
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
NLS_CHARACTERSET AL32UTF8
NLS_NCHAR_CHARACTERSET AL16UTF16
SQL>
SQL> select a,dump(a,1016) from test.cs_test where rownum<=5
SQL> /
A DUMP(A,1016)
------ --------------------------------------------------------------------------------
1234 Typ=1 Len=4 CharacterSet=AL32UTF8: 31,32,33,34
abcd Typ=1 Len=4 CharacterSet=AL32UTF8: 61,62,63,64
??瀹 Typ=1 Len=6 CharacterSet=AL32UTF8: e5,9b,9e,e5,ae,b6 <<<<<<<< 乱码
楂?? Typ=1 Len=6 CharacterSet=AL32UTF8: e9,ab,98,e5,85,b4 <<<<<<<< 乱码
濂界? Typ=1 Len=6 CharacterSet=AL32UTF8: e5,a5,bd,e7,8e,a9 <<<<<<<< 乱码
SQL>
如果设置成gbk,才能正确显示:
[oracle11g@testdb2 ~]$ export NLS_LANG=american_america.zhs16gbk
[oracle11g@testdb2 ~]$ sqlplus "/ as sysdba"
SQL*Plus: Release 11.2.0.4.0 Production on Wed Jun 22 18:13:56 2016
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, Oracle Label Security, OLAP, Data Mining
and Real Application Testing options
SQL> col dump(a,1016) for a80
SQL> select a,dump(a,1016) from test.cs_test where rownum<=5
SQL> /
A DUMP(A,1016)
------------ --------------------------------------------------------------------------------
1234 Typ=1 Len=4 CharacterSet=AL32UTF8: 31,32,33,34
abcd Typ=1 Len=4 CharacterSet=AL32UTF8: 61,62,63,64
回家 Typ=1 Len=6 CharacterSet=AL32UTF8: e5,9b,9e,e5,ae,b6
高兴 Typ=1 Len=6 CharacterSet=AL32UTF8: e9,ab,98,e5,85,b4
好玩 Typ=1 Len=6 CharacterSet=AL32UTF8: e5,a5,bd,e7,8e,a9
SQL>
总体来说nls_lang的作用是告诉oracle数据库服务器,当前的客户端用的是哪个字符集,是否需要转码。
设置nls_lang要看客户端(或者说工具端)的设置。有些客户端自己包含字符集(如adobe的一些产品,如ebs的产品,如peoplesoft的产品),有些客户端是继承操作系统的字符集,有些客户端是包含多个字符集,可以选择。要数据库服务器能正确转码,客户端登录数据库前,需要将nls_lang设置成客户端自己的字符集或者继承的字符集。
网上说要设置客户端的nls_lang和数据库端的字符集一样,并不是一种准确的说法。Oracle在文档中也提到这种做法NOT ALWAYS correct:
* Setting the NLS_LANG to the characterset of the database (NLS_CHARACTERSET) MAY be correct but IS NOT ALWAYS correct. Please DO NOT assume that NLS_LANG needs to be ALWAYS the same as the database characterset. THIS IS NOT TRUE.
* The characterset defined with the NLS_LANG parameter does NOT CHANGE your client's characterset, it is used to let Oracle know what characterset you are USING on the client side, so Oracle can do the proper conversion between the client's encoding and the NLS_CHARACTERSET.
相关文章
- 《弓箭传说2》新手玩法介绍 01-16
- 《地下城与勇士:起源》断桥烟雨多买多送活动内容一览 01-16
- 《差不多高手》醉拳龙技能特点分享 01-16
- 《鬼谷八荒》毕方尾羽解除限制道具推荐 01-16
- 《地下城与勇士:起源》阿拉德首次迎新春活动内容一览 01-16
- 《差不多高手》情圣技能特点分享 01-16