



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
mysql通过当前排序字段获取相邻数据项代码示例
时间:2022-06-29 08:32:59 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下mysql通过当前排序字段获取相邻数据项代码示例,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
通过当前排序字段获取相邻数据项
1.业务场景
(1)需要专门以一个弹窗页面展示一项数据的所有字段值.其中一些字段值长度较大。
(2)能够左右切换上一项下一项数据
(3)存在可排序的字段,如以id进行排序
2.思路
2.1 sql
1>查询前一项,查询小于当前id的项逆序取第一个
2>查询后一项,查询大于当前id的项正序取第一个
3>连接两项结果
2.2 页面逻辑
(1)在展示当前项时获取好两相邻的数据,在做切换时直接填充数据
(2)切换数据展示时同样再次获取当前项两相邻数据
以此(1)(2)往复
3.sql
例:查询id为40两相邻的数据
( SELECT * FROM [表名] WHERE id < 40 ORDER BY id DESC LIMIT 1 ) UNION
(
SELECT
*
FROM
[表名]
WHERE
id > 40
ORDER BY
id
LIMIT 1
)
同表相邻数据查询或计算
用户下相邻订单的时间差举例
这里主要介绍一下,在一张数据表下对相邻的数据进行一个相关查询和计算;
拿一个在电商中最常见的情况,计算一下用户首单和第二单的时间间隔这样的数据来举例,如下:
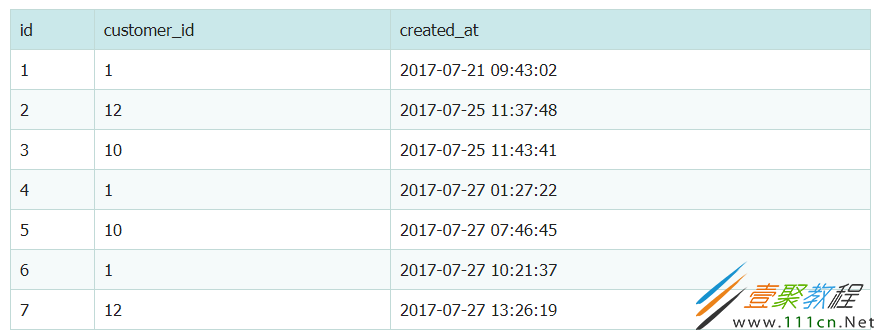
查询用户首单和第二单的时间间隔:
SELECT m.customer_id, sfo.created_at as '首单时间', m.created_at as '第二单时间', (unix_timestamp(m.created_at) - unix_timestamp(sfo.created_at))/86400 as '两单相差天数' FROM sales_flat_order m LEFT JOIN sales_flat_order sfo on m.customer_id = sfo.customer_id and sfo.created_at < m.created_at WHERE ( SELECT count(*) FROM sales_flat_order n WHERE m.customer_id = n.customer_id AND m.created_at > n.created_at ) = 1 GROUP BY m.customer_id
查询结果是:

整个原理如下:
将一张表查询两次得到两组数据,分别为别名m和别名n的两组数据;
以m为主,用n的数据和m的数据作对比,通过created_at的判断过滤掉一些无用数据;
使用count()函数统计满足条件的数据个数;
统计数为1时说明n表中比m表中时间小的只有1条,m中的该条数据也就是该用户下的第二笔订单;
通过LEFT JOIN联表,通过created_at找到比第二单更早的一单也就是用户的首单;
利用unix_timestamp把得到的两条数据的created_at做差,得到了两笔订单的时间间隔;
下面做了一下拓展,可以查询任意相连的两笔订单的时间间隔:
SELECT m.customer_id, m.created_at as '后一单时间', SUBSTRING_INDEX( GROUP_CONCAT(sfo.created_at ORDER BY sfo.created_at DESC), ',', 1 ) as '前一单时间', (unix_timestamp(m.created_at) - unix_timestamp( SUBSTRING_INDEX( GROUP_CONCAT(sfo.created_at ORDER BY sfo.created_at DESC), ',', 1 ) ))/86400 as '两单相差天数' FROM sales_flat_order m LEFT JOIN sales_flat_order sfo on m.customer_id = sfo.customer_id and sfo.created_at < m.created_at WHERE ( SELECT count(*) FROM sales_flat_order n WHERE m.customer_id = n.customer_id AND m.created_at > n.created_at ) = 2 GROUP BY m.customer_id;
得到数据如下:

这里判断的是统计数为2的,也就是用户的第二单和第三单的时间间隔计算,因为用户10和12只有两单所以结果中无这两个用户;
整个原理如下:
将一张表查询两次得到两组数据,分别为别名m和别名n的两组数据;
以m为主,用n的数据和m的数据作对比,通过created_at的判断过滤掉一些无用数据;
使用count()函数统计满足条件的数据个数;
筛选之后m中得到的是第三笔订单;
通过LEFT JOIN联表,通过created_at找到比第三笔订单时间早的订单,这里会从sfo中得到两笔订单;
利用GROUP_CONCAT函数每组订单中各得到的两笔订单利用created_at进行降序排序,然后得到通过‘,’连接的两条数据的时间,如下:2017-07-27 01:27:22,2017-07-21 09:43:02
使用SUBSTRING_INDEX函数通过’,'将数据拆分再拿到第一条数据,也就是第二笔订单的时间了;
利用unix_timestamp对created_at作差,得到两笔订单的时间间隔;
相关文章
- 《弓箭传说2》新手玩法介绍 01-16
- 《地下城与勇士:起源》断桥烟雨多买多送活动内容一览 01-16
- 《差不多高手》醉拳龙技能特点分享 01-16
- 《鬼谷八荒》毕方尾羽解除限制道具推荐 01-16
- 《地下城与勇士:起源》阿拉德首次迎新春活动内容一览 01-16
- 《差不多高手》情圣技能特点分享 01-16