



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
防止MySQL重复插入数据的三种方法
时间:2022-06-29 08:51:05 编辑:袖梨 来源:一聚教程网
本篇文章小编给大家分享一下防止MySQL重复插入数据的三种方法,文章代码介绍的很详细,小编觉得挺不错的,现在分享给大家供大家参考,有需要的小伙伴们可以来看看。
新建表格
CREATE TABLE `person` ( `id` int NOT NULL COMMENT '主键', `name` varchar(64) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '姓名', `age` int NULL DEFAULT NULL COMMENT '年龄', `address` varchar(512) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '地址', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
添加三条数据如下:
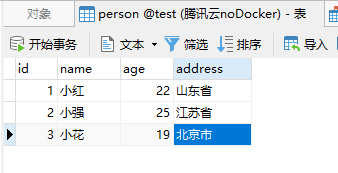
我们这边可以根据插入方式进行规避:
1. insert ignore
insert ignore 会自动忽略数据库已经存在的数据(根据主键或者唯一索引判断),如果没有数据就插入数据,如果有数据就跳过插入这条数据。
--插入SQL如下: insert ignore into person (id,name,age,address) values(3,'那谁',23,'甘肃省'),(4,'我的天',25,'浙江省');
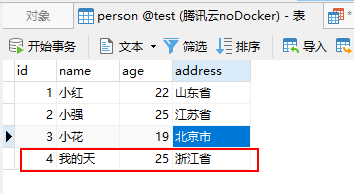
再次查看数据库就会发现仅插入id为4的数据,由于数据库中存在id为3的数据所以被忽略。
2. replace into
replace into 首先尝试插入数据到表中, 1. 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。 2. 否则,直接插入新数据。
--插入SQL如下: replace into person (id,name,age,address) values(3,'那谁',23,'甘肃省'),(4,'我的天',25,'浙江省');
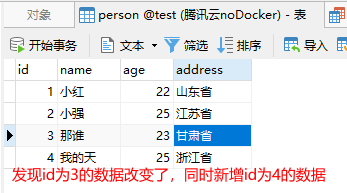
首先我们将表中数据恢复,然后进行插入操作后发现id为3的数据发生了改变同时新增了id为4的数据。
3. insert on duplicate key update
insert on duplicate key update 如果在insert into语句的末尾指定了on duplicate key update + 字段更新,则会在出现重复数据(根据主键或者唯一索引判断)的时候按照后面字段更新的描述对该信息进行更新操作。
--插入SQL如下: insert into person (id,name,age,address) values(3,'那谁',23,'甘肃省') on duplicate key update name='那谁', age=23, address='甘肃省';
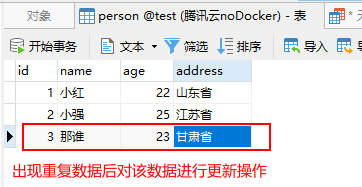
首先我们将表中数据恢复,然后在进行插入操作时,发现id为3的数据发生了改变,进行了更新操作。
我们可以根据自己的业务需求进行方法的选择。
相关文章
- 《弓箭传说2》新手玩法介绍 01-16
- 《地下城与勇士:起源》断桥烟雨多买多送活动内容一览 01-16
- 《差不多高手》醉拳龙技能特点分享 01-16
- 《鬼谷八荒》毕方尾羽解除限制道具推荐 01-16
- 《地下城与勇士:起源》阿拉德首次迎新春活动内容一览 01-16
- 《差不多高手》情圣技能特点分享 01-16