



最新下载
热门教程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Python之Scrapy爬虫框架安装及简单使用详解
时间:2022-06-29 13:42:41 编辑:袖梨 来源:一聚教程网
题记:早已听闻python爬虫框架的大名。近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享。有表述不当之处,望大神们斧正。
一、初窥Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫。
本文档将通过介绍Scrapy背后的概念使您对其工作原理有所了解, 并确定Scrapy是否是您所需要的。
当您准备好开始您的项目后,您可以参考入门教程。
二、Scrapy安装介绍
Scrapy框架运行平台及相关辅助工具
- Python2.7(Python最新版3.5,这里选择了2.7版本)
- Python Package:pipandsetuptools. 现在pip依赖setuptools,如果未安装,则会自动安装setuptools。
- lxml. 大多数Linux发行版自带了lxml。如果缺失,请查看http://lxml.de/installation.html
- OpenSSL. 除了Windows(请查看平台安装指南)之外的系统都已经提供。
您可以使用pip来安装Scrapy(推荐使用pip来安装Python package).
pip install Scrapy
Windows下安装流程:
1、安装Python 2.7之后,您需要修改PATH环境变量,将Python的可执行程序及额外的脚本添加到系统路径中。将以下路径添加到PATH中:
C:Python27;C:Python27Scripts;
除此之外,还可以用cmd命令来设置Path:
c:python27python.exe c:python27toolsscriptswin_add2path.py
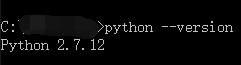
安装配置完成之后,可以执行命令python --version查看安装的python版本。(如图所示)
2、从http://sourceforge.net/projects/pywin32/安装pywin32
请确认下载符合您系统的版本(win32或者amd64)
从https://pip.pypa.io/en/latest/installing.html安装pip
3、打开命令行窗口,确认pip被正确安装:
pip --version
4、到目前为止Python 2.7 及pip已经可以正确运行了。接下来安装Scrapy:
pip install Scrapy
至此windows下Scrapy安装已经结束。
三、Scrapy入门教程
1、在cmd中创建Scrapy项目工程。
scrapy startproject tutorial
H:pythonscrapyDemo>scrapy startproject tutorial New Scrapy project 'tutorial', using template directory 'f:python27libsite-packagesscrapytemplatesproject', created in: H:pythonscrapyDemotutorial You can start your first spider with: cd tutorial scrapy genspider example example.com
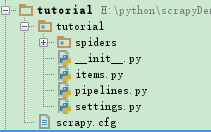
2、文件目录结构如下:
 。
。
解析scrapy框架结构:
-
scrapy.cfg: 项目的配置文件。 -
tutorial/: 该项目的python模块。之后您将在此加入代码。 -
tutorial/items.py: 项目中的item文件。 -
tutorial/pipelines.py: 项目中的pipelines文件。 -
tutorial/settings.py: 项目的设置文件。 -
tutorial/spiders/: 放置spider代码的目录。
3、编写简单的爬虫
1、在item.py中配置需采集页面的字段实例。
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy from scrapy.item import Item, Field class TutorialItem(Item): title = Field() author = Field() releasedate = Field()
2、在tutorial/spiders/spider.py中书写要采集的网站以及分别采集各字段。
# -*-coding:utf-8-*-
import sys
from scrapy.linkextractors.sgml import SgmlLinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from tutorial.items import TutorialItem
reload(sys)
sys.setdefaultencoding("utf-8")
class ListSpider(CrawlSpider):
# 爬虫名称
name = "tutorial"
# 设置下载延时
download_delay = 1
# 允许域名
allowed_domains = ["news.cnblogs.com"]
# 开始URL
start_urls = [
"https://news.cnblogs.com"
]
# 爬取规则,不带callback表示向该类url递归爬取
rules = (
Rule(SgmlLinkExtractor(allow=(r'https://news.cnblogs.com/n/page/d',))),
Rule(SgmlLinkExtractor(allow=(r'https://news.cnblogs.com/n/d+',)), callback='parse_content'),
)
# 解析内容函数
def parse_content(self, response):
item = TutorialItem()
# 当前URL
title = response.selector.xpath('//div[@id="news_title"]')[0].extract().decode('utf-8')
item['title'] = title
author = response.selector.xpath('//div[@id="news_info"]/span/a/text()')[0].extract().decode('utf-8')
item['author'] = author
releasedate = response.selector.xpath('//div[@id="news_info"]/span[@class="time"]/text()')[0].extract().decode(
'utf-8')
item['releasedate'] = releasedate
yield item
3、在tutorial/pipelines.py管道中保存数据。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
import codecs
class TutorialPipeline(object):
def __init__(self):
self.file = codecs.open('data.json', mode='wb', encoding='utf-8')#数据存储到data.json
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "n"
self.file.write(line.decode("unicode_escape"))
return item
4、tutorial/settings.py中配置执行环境。
# -*- coding: utf-8 -*-
BOT_NAME = 'tutorial'
SPIDER_MODULES = ['tutorial.spiders']
NEWSPIDER_MODULE = 'tutorial.spiders'
# 禁止cookies,防止被ban
COOKIES_ENABLED = False
COOKIES_ENABLES = False
# 设置Pipeline,此处实现数据写入文件
ITEM_PIPELINES = {
'tutorial.pipelines.TutorialPipeline': 300
}
# 设置爬虫爬取的最大深度
DEPTH_LIMIT = 100
5、新建main文件执行爬虫代码。
from scrapy import cmdline
cmdline.execute("scrapy crawl tutorial".split())
最终,执行main.py后在data.json文件中获取到采集结果的json数据。

相关文章
- 《弓箭传说2》新手玩法介绍 01-16
- 《地下城与勇士:起源》断桥烟雨多买多送活动内容一览 01-16
- 《差不多高手》醉拳龙技能特点分享 01-16
- 《鬼谷八荒》毕方尾羽解除限制道具推荐 01-16
- 《地下城与勇士:起源》阿拉德首次迎新春活动内容一览 01-16
- 《差不多高手》情圣技能特点分享 01-16